What is robots.txt?
Robots.txt is a file instructing search engine crawler bots and other bots about the pages they can and cannot crawl on a website. The file is named robots.txt and is located in the site’s root folder.
The robots.txt file helps protect sensitive information, reduce server load, and influence how search engines crawl a site. This is how it appears on a site.
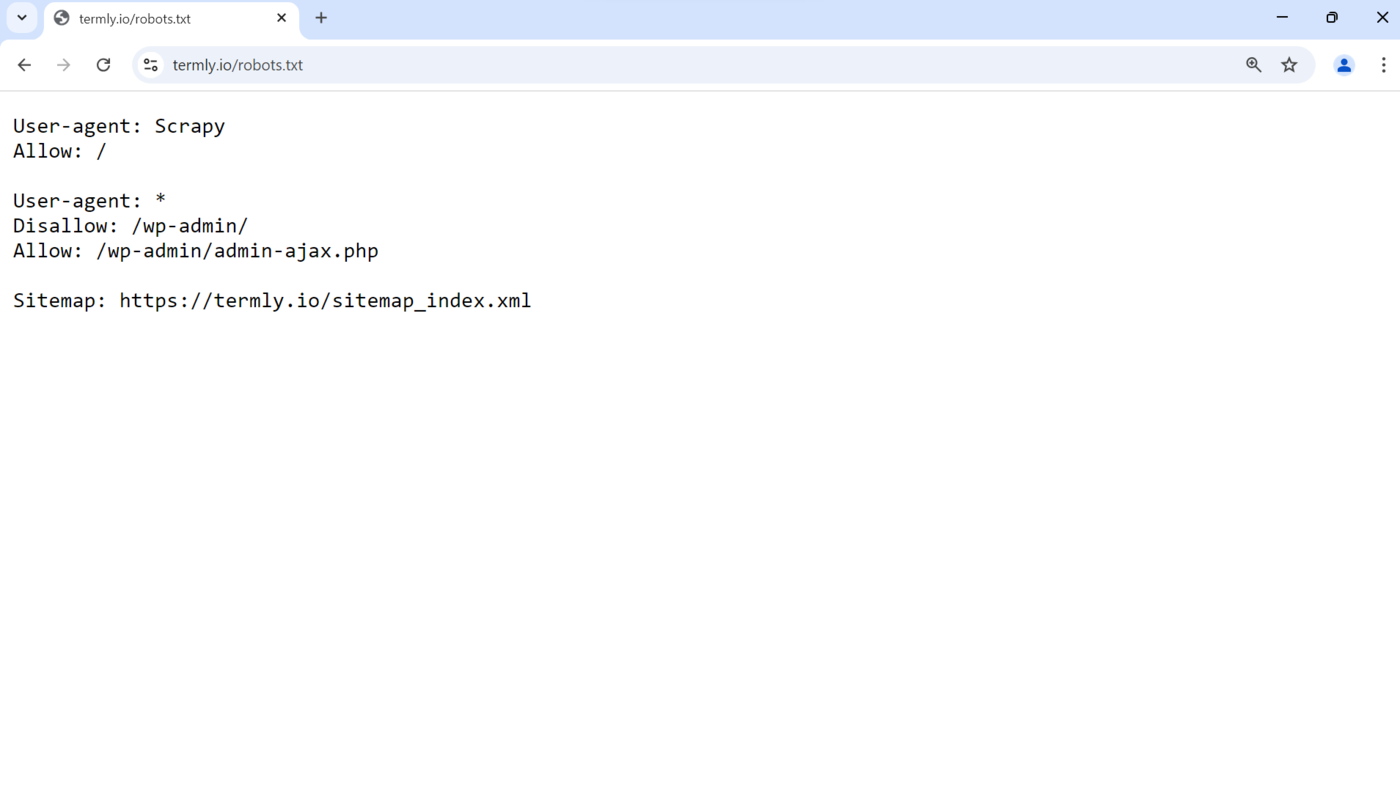
It is essential to note that while search engine crawler bots generally obey the rules in the robots.txt file, other crawler bots may decide to crawl the links even if you instructed them not to.
You can easily add a robots.txt file to your site by installing Rank Math SEO. After installation, Rank Math will automatically generate a robots.txt file for you. You can typically view this file at https://yourdomain.com/robots.txt. (Ensure to replace yourdomain.com with your site name.)
In this article, we’ll cover:
How to Locate Your robots.txt File
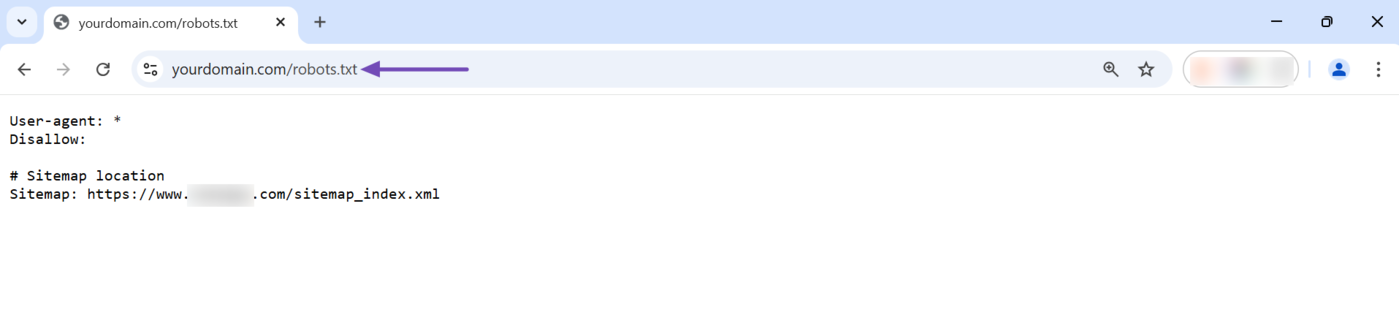
The robots.txt file should be located in your site’s root folder. You can access it at yourdomain.com/robots.txt. Just replace yourdomain.com with your domain name and enter it into your address bar. It will reveal your robots.txt file.
In the case of a subdomain like blog.yourdomain.com, the robots.txt file will be located at blog.yourdomain.com/robots.txt.
How to Inspect and Validate Your robots.txt File
You may want to review your robots.txt file to ensure it is valid and works as you want it to. You can do so using two tools:
- Robots.txt Tester and Validator tool
- Google Search Console
Let us show you how to use both tools.
1 Robots.txt Tester and Validator Tool
The robots.txt tester and validator tool allows you to validate your robots.txt file and simulate how multiple user-agents interpret it.
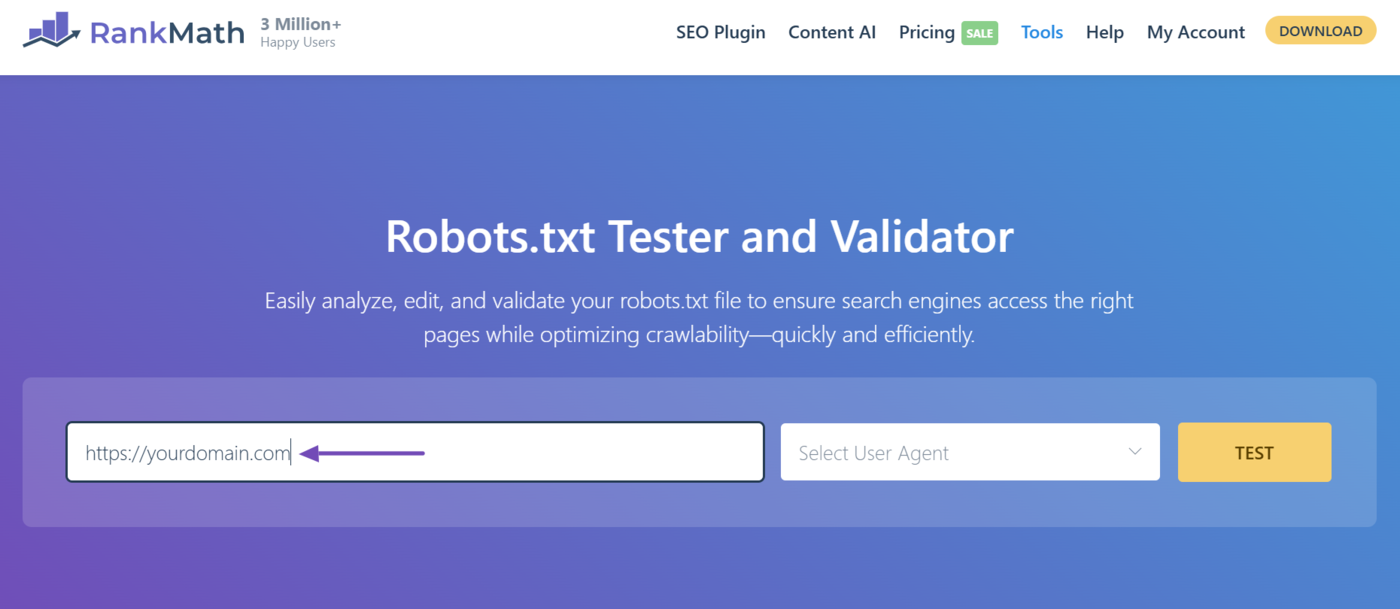
To get started, head to the robots.txt Tester and Validator tool. Once done, enter your URL into the relevant field, as shown below.
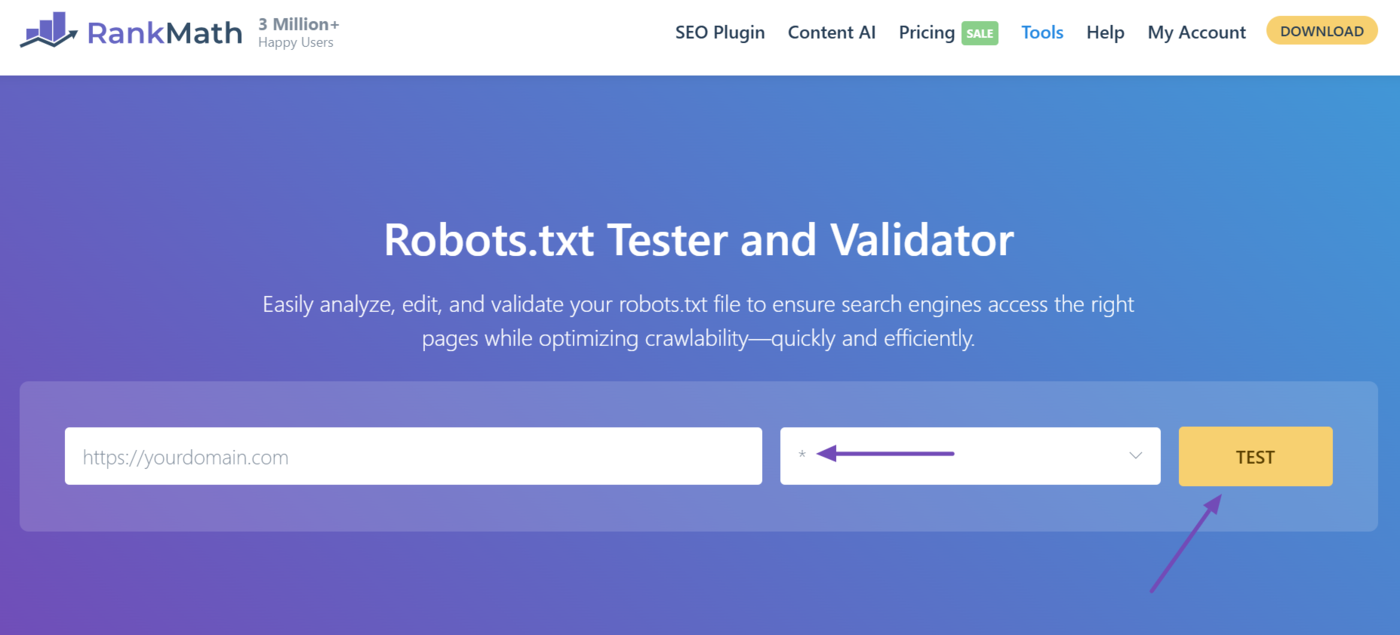
Then, select a user-agent to simulate how it interprets your rule. To see how every user-agent interprets your file, select the asterisk symbol *. Once done, click Test.
The tool will return with your robots.txt test results. This result contains the rules in your robots.txt file. It also contains additional information. Here, it confirms that our file does not contain unknown, contradictory, or unclear rules.
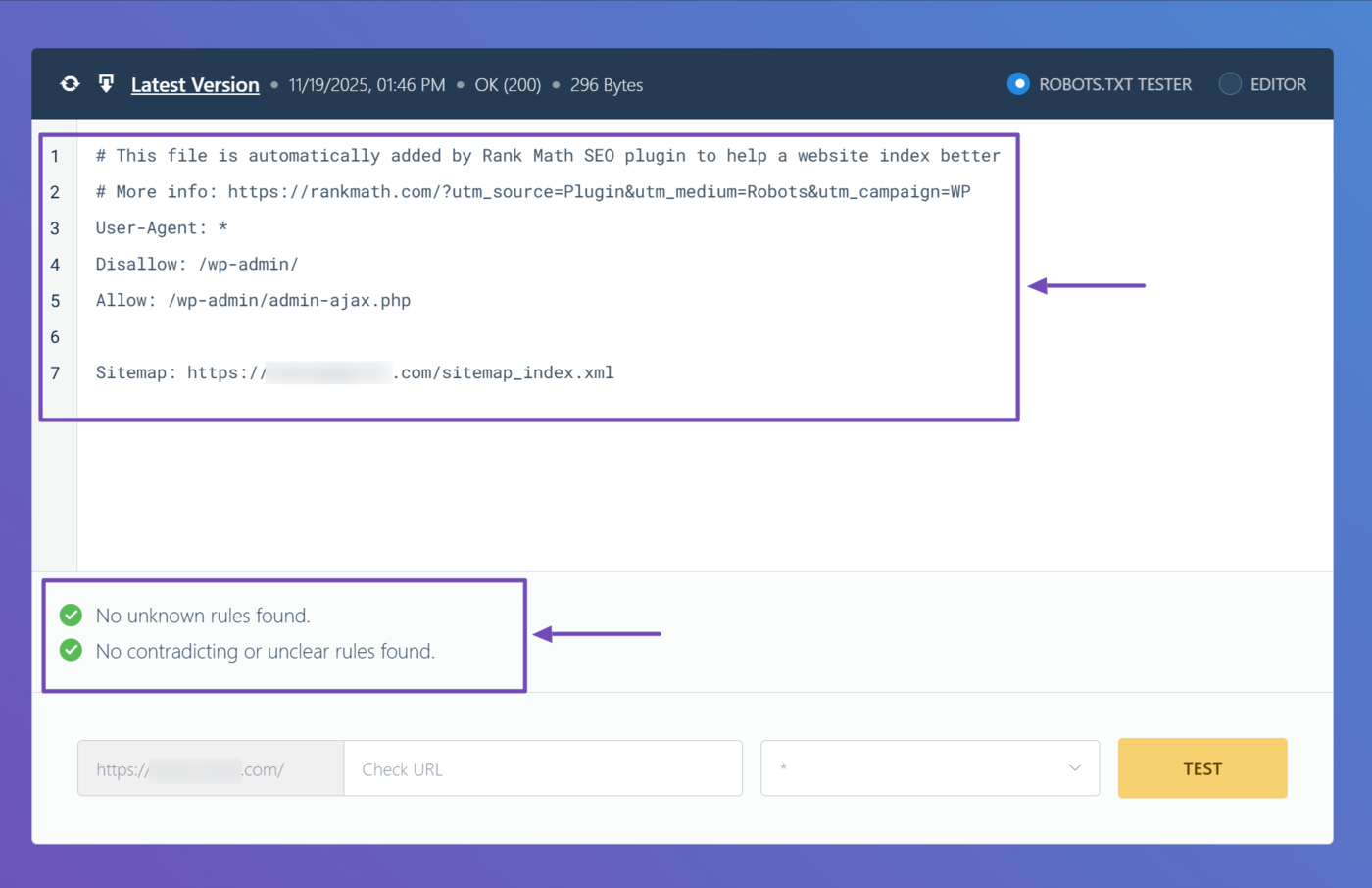
2 Google Search Console
Google Search Console allows you to identify whether Googlebot can find and access your robots.txt file.
To get started, log into your Google Search Console account. Then, scroll down the left sidebar and click Settings.
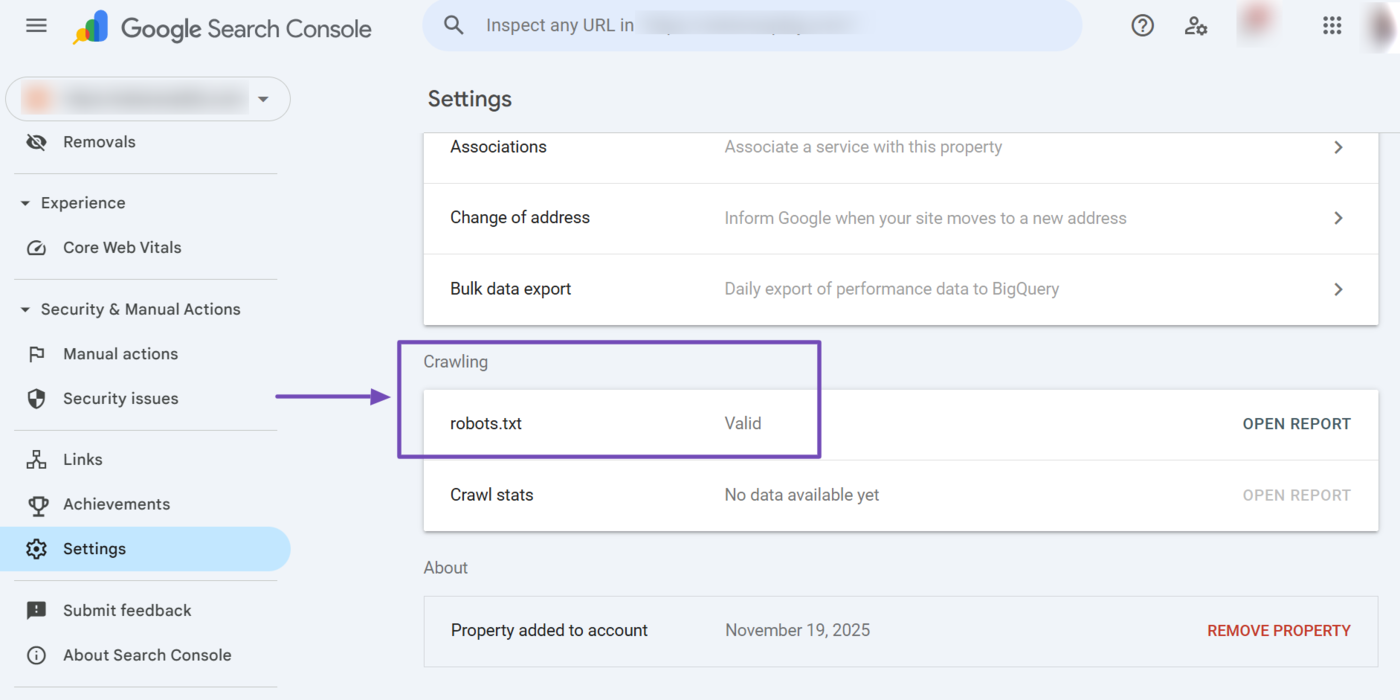
Now, scroll down to Crawling → robots.txt. Here, you will find the validity status of your robots.txt file.
- If your robots.txt file is valid, it will display a “valid” message, as shown below
- If your robots.txt file is invalid, it will display an error message indicating such
To gather more insights into your robots.txt file, click Open report.
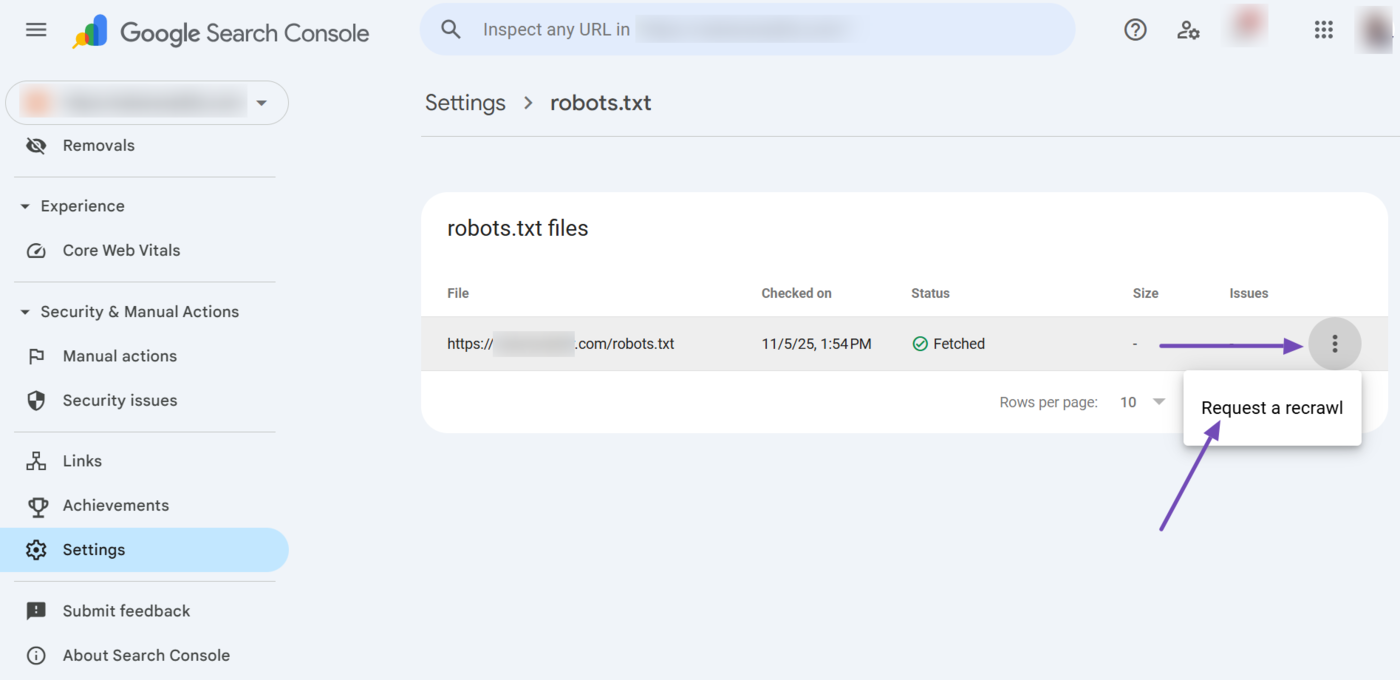
You will see some information about your robots.txt file including its URL, the last time Google checked it, and its crawl status. If you want Google to recrawl it, click the menu icon and the select Request a recrawl.
List of Some Common robots.txt User-Agents
Robots.txt rules typically consist of a user-agent and one or more directives. The user-agent specifies the web crawlers for which the directive is intended. It is declared using the user-agent string. For example: User-agent: *
Some common user-agents include:
*: The rule is directed at all crawler botsGooglebot: The rule is directed at Google’s crawler botGooglebot-Image: The rule is directed at Google Images crawler botBingbot: The rule is directed at Bing’s crawler botSlurp: The rule is directed at Yahoo’s crawler botYandexBot: The rule is directed at Yandex’s crawler botGPTBot: The rule is directed at OpenAI’s crawler bot
Note: The asterisk * user-agent is called the wildcard character.
Let us show you some use cases of a user-agent.
For example, if you do not want any search engine crawler to crawl your site, you will pair the wildcard * user-agent with the Disallow: / directive, as shown below.
User-agent: * Disallow: /
The above directive tells all search engine crawlers to not crawl your site.
However, if you want to stop a specific crawler from crawling your site, you will use the crawler’s user-agent with the disallow directive. For example:
User-agent: Googlebot Disallow: /
The above rule instructs Googlebot to not crawl your site. However, it allows other crawlers to crawl your site.
List of Some Common robots.txt Directives
Directives are the commands and instructions that inform web crawlers about what part of the site they can and cannot crawl and how they are expected to crawl it. Some common robots.txt directives include:
- Disallow
- Allow
- Sitemap
- Crawl-delay
1 Disallow
The disallow directive tells web crawlers which URLs they cannot access or index. For example, the rule below tells all search engines not to crawl any page on your site.
User-agent: * Disallow: /
Similarly, the disallow directive below instructs all crawlers to not crawl URLs that match the /wp-admin/ path.
User-agent: * Disallow: /wp-admin/
This means search engines will not crawl URLs like:
- yourdomain.com/wp-admin/
- yourdomain.com/wp-admin/edit.php
2 Allow
The allow directive tells web crawlers which URLs they can crawl and index. However, search engines assume they are allowed to crawl all URLs on a site unless there is a disallow rule blocking them from doing so. So, there is no need to include an allow directive with your URLs.
Instead, the allow directive is only used when you want search engines to crawl specific subpaths within a path you already blocked them from crawling. In other words, the allow directive is only used with a disallow directive.
For example, the rule below blocks search engines from crawling URLs within the /paid-course/ path. However, there is a directive allowing them to crawl URLs within the /paid-course/chapter-one/ subpath.
User-agent: * Disallow: /paid-course/ Allow: /paid-course/chapter-one
This means search engines will crawl URLs like:
- yourdomain.com/paid-course/chapter-one
- yourdomain.com/paid-course/chapter-one/section-one
However, search engines will not crawl URLs like:
- yourdomain.com/paid-course/
- yourdomain.com/paid-course/chapter-two
3 Sitemap
The sitemap specifies the location of the site’s XML sitemap. It does not include a user-agent and is declared using the sitemap string.
Sitemap: https://yourdomain.com/sitemap_index.xml
The robots.txt file can contain multiple sitemaps. In such situations, each sitemap will be declared separately. For example:
Sitemap: https://yourdomain.com/post-sitemap.xml Sitemap: https://yourdomain.com/page-sitemap.xml Sitemap: https://yourdomain.com/product-sitemap.xml
4 Crawl-Delay
The crawl-delay directive recommends the rate at which a blogger wants search engines to crawl their site. It is crucial to know that not all crawlers obey this directive. For instance, Google and Yandex do not obey it, but Bing does.
Additionally, search engines may interpret the crawl delay rule differently. For example, some crawlers may assume that the rule below instructs them to access a URL once every 10 seconds or wait 10 seconds between requests.
User-agent: * Crawl-delay: 10
Some robots.txt Best Practices You Should Follow
An incorrectly configured robots.txt file could have serious consequences for your SEO. To reduce the possibility of such happening, it is recommended to follow the best practices listed below.
1 Do Not Create Conflicting Rules
It is easy to create conflicting rules in a robots.txt file. This is particularly common in files that contain multiple complex rules. For example, you may unknowingly allow and disallow crawlers from crawling the same URL.
Such contradictory rules confuse crawlers and could cause them to perform some other action than the one you intended them to. Some crawlers resolve conflicting directives by obeying the first rule. Others follow the rule with the least number of characters or the one they consider less restrictive.
2 Do Not Use the robots.txt File to Hide Your Pages
The primary purpose of the robots.txt file is to manage the behavior of the crawler bots that access a site. It is not intended to hide pages from search engines. So, avoid using it to hide the URLs you do not want search engines to index.
Google can still find those pages and could display them on search results pages if they receive a link from another content. Instead, use the noindex meta tag to specify URLs you do not want search engines to index.
3 Include Your Sitemap in Your robots.txt File
While search engines can find your content without a sitemap, it is good practice to include one on your site. When you do, add the sitemap’s URL to your robots.txt file.
Search engines will typically check specific locations on your site to see if it contains a sitemap. However, including it in your robots.txt file speeds up the discovery process and informs them of its location.
4 Use a Separate robots.txt Rule for Your Subdomain
Robots.txt files only tell search engines how to crawl a specific domain or subdomain. If you have a subdomain, you have to create their robots.txt file separately.
For example, if you have a domain at yourdomain.com and a subdomain at shop.yourdomain.com, both URLs must have their separate robots.txt files as the robots.txt file of yourdomain.com will not control the crawling behavior for the URLs at shop.yourdomain.com.
5 Use the Correct Title Case for Your User-Agents
User-agents are case-sensitive. For example, Google’s crawler bot is called Googlebot. You must use this exact name when specifying a rule directed to it. The capital G and the rest in small letters.
Any rule you declare using user-agents like googlebot, googleBot, and GoogleBot will not work. It must be Googlebot. So, use the crawler bot’s name as specified by its developer.
6 Understand Which User-Agents Search Engines Obey
Most search engines have multiple crawlers for crawling different types of content, and they do not obey all rules directed to these crawlers.
For example, Google has multiple crawlers but only obeys rules directed at Googlebot and Googlebot-Image. So, before creating rules, check the documentation and confirm whether they obey directives directed to that user-agent.
7 Understand Which Directives Search Engines Obey
Search engines do not obey all directives. For example, Google does not obey the crawl-delay directive. So, review the search engine guidelines before creating your directives.