What Is TF-IDF?
TF-IDF, or Term Frequency-Inverse Document Frequency, is a statistical method for detecting the most important words in a document. It measures how important a word is to a document in relation to a collection of documents.
In simple terms, TF-IDF measures how frequently a word appears in an article while adjusting for commonly used words that occur more often. This prevents common terms from skewing the results and ensures that more meaningful words are given greater importance.
TF-IDF is made up of two components:
- Term frequency (TF)
- Inverse document frequency (IDF)
It is calculated by multiplying TF by IDF.

TF-IDF increases when a word frequently appears in a specific document (TF) but decreases when the word appears across many documents (IDF). The higher the TF-IDF value, the more important a term is to a document relative to the rest of the documents in the collection.
In this article, we’ll cover:
Understanding TF-IDF in Detail
Think of your website as a magazine and each webpage as an article in the magazine. Term frequency (TF) counts how often a specific word appears in an article.
For example, if our magazine contains an article about the history of music, the article will repeatedly contain words like “rhythm” and “melody.” This indicates the article is primarily focused on music.

However, the article on the history of music will also contain words such as “the” and “and,” which are common words that appear in almost every article, regardless of topic.
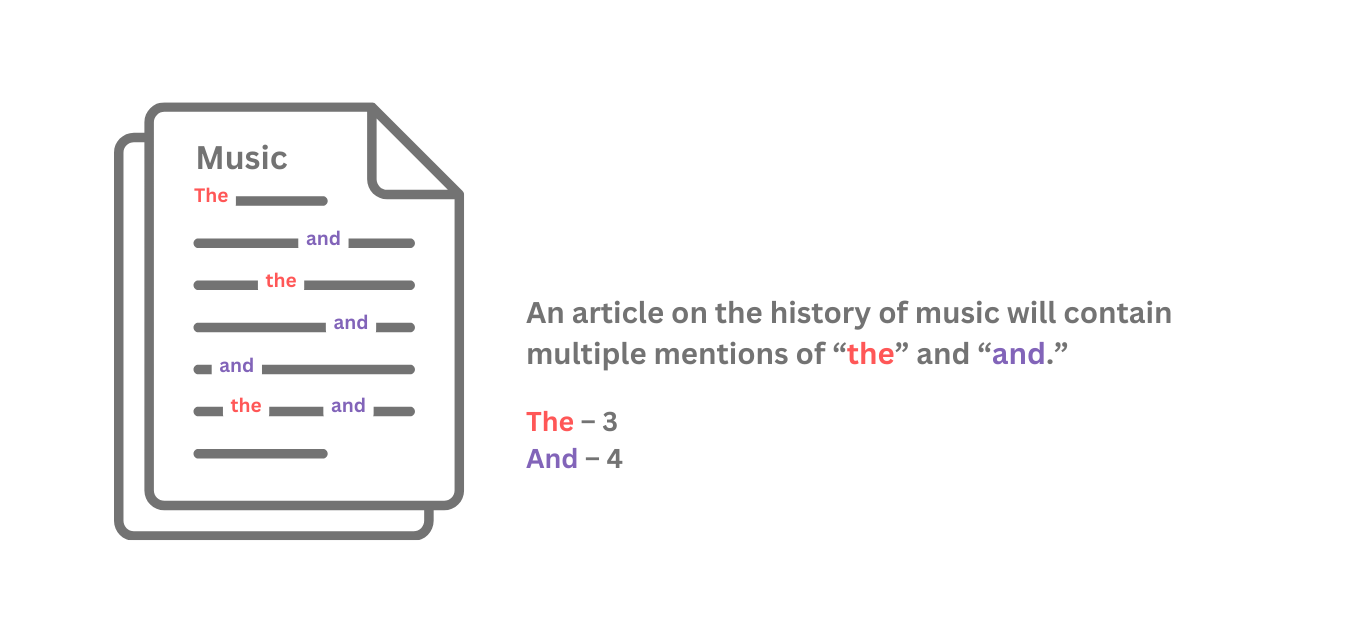
This is where inverse document frequency (IDF) comes in. IDF checks whether the words identified by term frequency (TF) also appear in other articles. Using our example, IDF evaluates how often the words below appear in the other articles in the magazine:
- Rhythm
- Melody
- The
- And
Let us say our magazine also contains articles on the history of dance and the history of food. Inverse document frequency will evaluate how frequently “rhythm,” “melody,” “the,” and “and” appear in them.
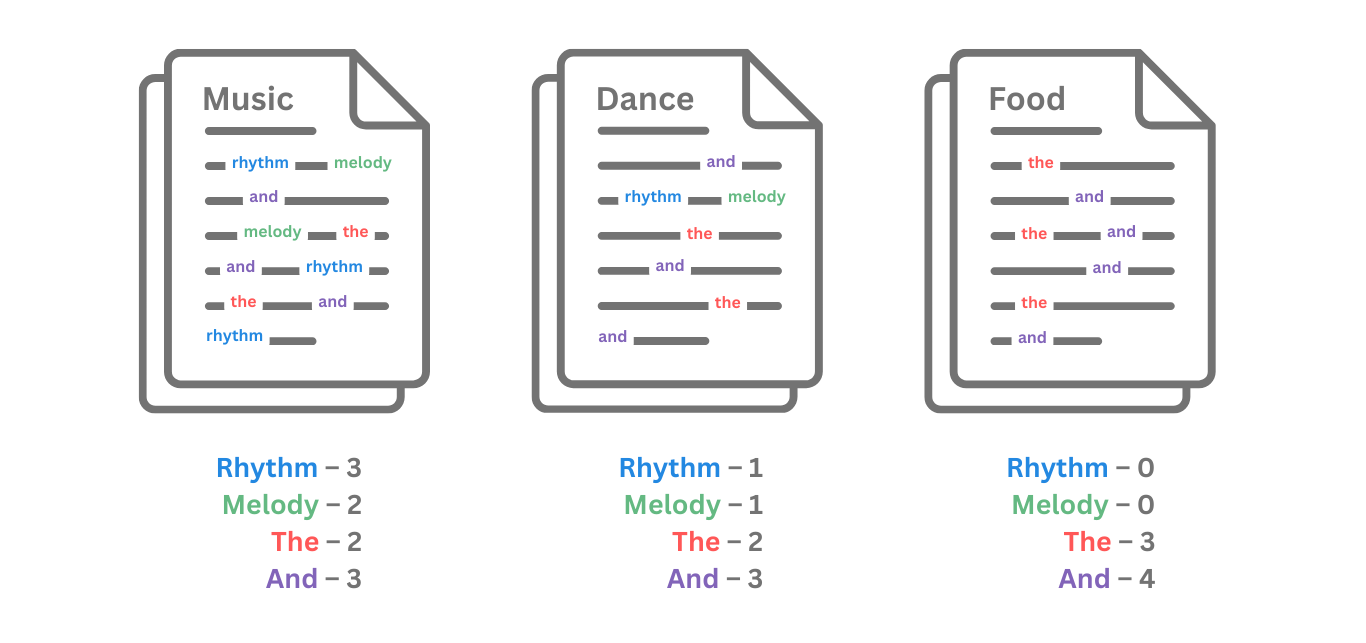
Words such as “the” and “and,” which appear in all three articles, are considered less important to the history of music article. In contrast, words that appear less frequently across the articles, such as “rhythm” and “melody,” are considered more important to the history of music article.
Components of TF-IDF
The term frequency-inverse document frequency (TF-IDF) consists of two components:
- Term frequency (TF)
- Inverse document frequency (IDF)
Let us explain them in more detail.
1 Term Frequency (TF)
Term frequency (TF) measures how often a word appears in a document. A higher term frequency indicates a term appears more often and is likely significant to the document.
The term frequency is calculated by dividing the number of times a term appears in a document by the total number of terms in the document.

For example, if a document contains 100 words and the word “banana” appears 5 times, then the term frequency (TF) of “banana” will be 5 / 100 = 0.05.
2 Inverse Document Frequency (IDF)
Inverse document frequency (IDF) measures how often a word appears across a collection of documents. Words that occur in fewer documents receive a higher IDF value, indicating they are more significant to a specific article in the collection.
Inverse document frequency is calculated by dividing the total number of documents by the number of documents containing the term, and then taking the logarithm of the result. To prevent errors when a term does not appear in any document, it is good practice to add one to the denominator.

For example, if you have 1,000 documents, and “banana” appears in 10 of them, then the inverse document frequency (IDF) will be log(1000 / (1 + 10)) = 1.96.
How to Calculate TF-IDF
The term frequency-inverse document frequency (TF-IDF) is calculated by multiplying the term frequency (TF) by the inverse document frequency (IDF). In other words, TF-IDF = TF × IDF.
Let us assume we have three documents, each containing a single sentence:
- Document a – The boy reads a book.
- Document b – The girl eats a banana.
- Document c – The boy and girl are friends.
Now, we want to see how important the words, “the” and “banana,” are to document b. To do that, we will calculate the TF, IDF, and finally, the TF-IDF for “the” and “banana” across all three documents.
1 Calculate the Term Frequency (TF)
The term frequency is the number of times “the” and “banana” appear in a document divided by the total number of words in that document.

Here, the term frequency for “the” across each document is:
- Document a – 0.2
- Document b – 0.2
- Document c – 0.17
Similarly, the term frequency for “banana” is:
- Document a – 0
- Document b – 0.2
- Document c – 0
2 Calculate the Inverse Document Frequency (IDF)
Inverse document frequency measures how often “the” and “banana” appear across all three articles. In this example, the IDF of “the” is –0.12, while the IDF of “banana” is 0.18.

3 Calculate TF-IDF
TF-IDF is calculated by multiplying term frequency by inverse document frequency.
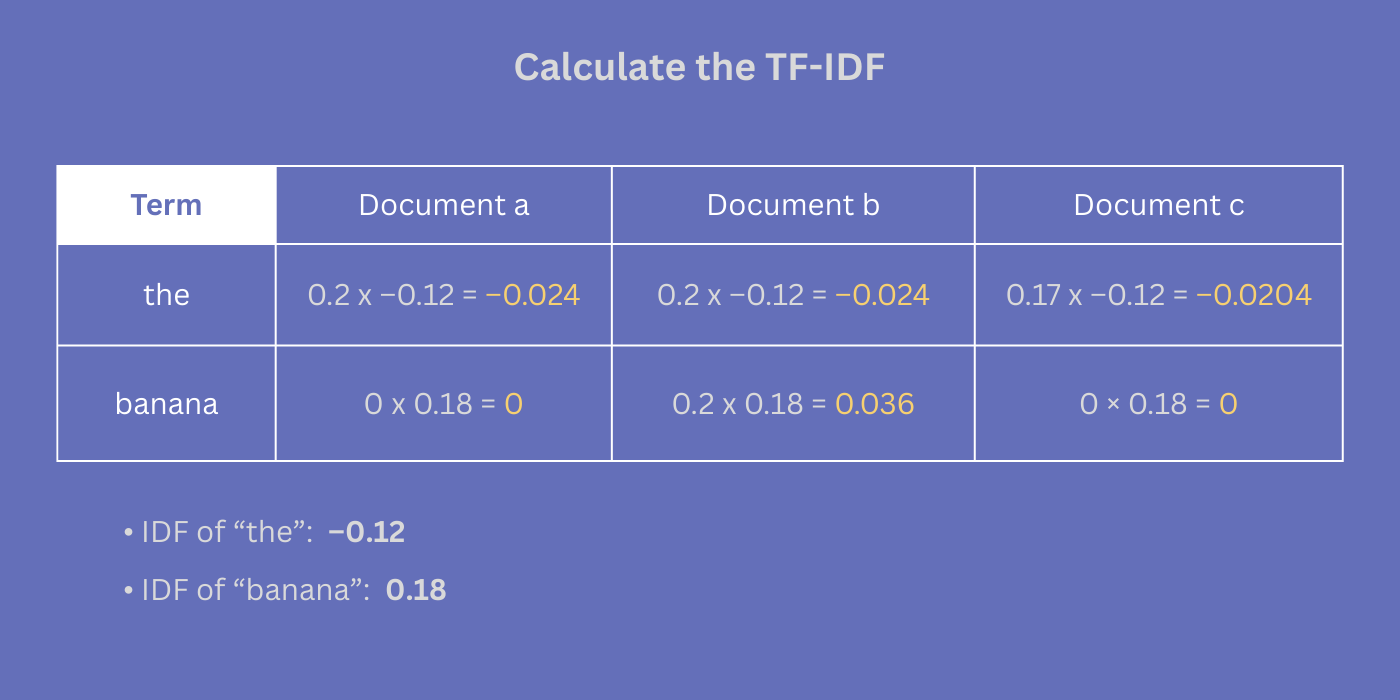
Across our documents, the TF-IDF of “the” is:
- Document a: –0.024
- Document b: –0.024
- Document c: –0.0204
On the other hand, the TF-IDF of “banana” is:
- Document a: 0
- Document b: 0.036
- Document c: 0
Within document b, the TF-IDF of “the” is –0.024 while that of “banana” is 0.036.
0.036 is greater than –0.024, which means banana is more important than “the” in document b. In other words, document b is likelier to be about bananas than about the word “the.”
Uses of TF-IDF
SEO tools and search engines use TF-IDF to identify the main content on a webpage. This can then be applied to various tasks, including content research, spam detection, and improving the user experience.
1 How Search Engines Use TF-IDF
Search engines have historically used TF-IDF to identify the important words on a webpage. They also use it for additional purposes, including the detection of spammy and duplicate content.
However, TF-IDF is not a direct ranking factor, and is typically complemented (or even replaced) by more advanced systems such as artificial intelligence, machine learning, and semantic analysis, which allow search engines to understand the meaning and context of the words.
2 How SEO Tools Use TF-IDF
SEO tools use TF-IDF to identify relevant keywords and internal links that creators can include in their content. They also use TF-IDF to decide the topics and keywords they return to creators during keyword and topic research.
In addition, related content plugins use TF-IDF to detect relevant articles to include on a webpage. This ensures visitors to the webpage are directed to relevant content related to the one they already accessed.
TF-IDF Frequently Asked Questions (FAQs)
How is TF-IDF calculated?
TF-IDF is calculated by multiplying term frequency (TF) and inverse document frequency (IDF) for each term. TF measures how often a word appears in a document, while IDF reduces the weight of words that appear in many documents.
What is the difference between TF and IDF?
TF (term frequency) measures how often a word appears in a single document, while IDF (inverse document frequency) evaluates how rare a word is across multiple documents. In other words, TF shows importance within a document, while IDF shows importance across a collection of documents.
Is TF-IDF a ranking factor for Google?
TF-IDF itself is not a direct Google ranking factor, but it can indirectly influence SEO. Google’s algorithms may favor content that naturally includes important and unique terms, which TF-IDF, along with other systems such as machine learning and semantic analysis, can help identify.
What are the limitations of TF-IDF?
TF-IDF ignores word order and semantic meaning, so it cannot understand context. It treats terms independently and may give high weight to rare but irrelevant words. Additionally, it is less effective for very short texts or large datasets.
Can TF-IDF handle synonyms or related terms?
No, TF-IDF cannot recognize synonyms or related words because it treats each word as unique. Words with similar meanings are counted separately, which can limit its effectiveness in understanding semantic relationships.