If you’ve received an email alert or happen to notice the warning ‘Indexed, though blocked by robots.txt’ in your Google Search Console, as shown below, then in this knowledgebase article, we’ll show you how to troubleshoot the warning and fix it.
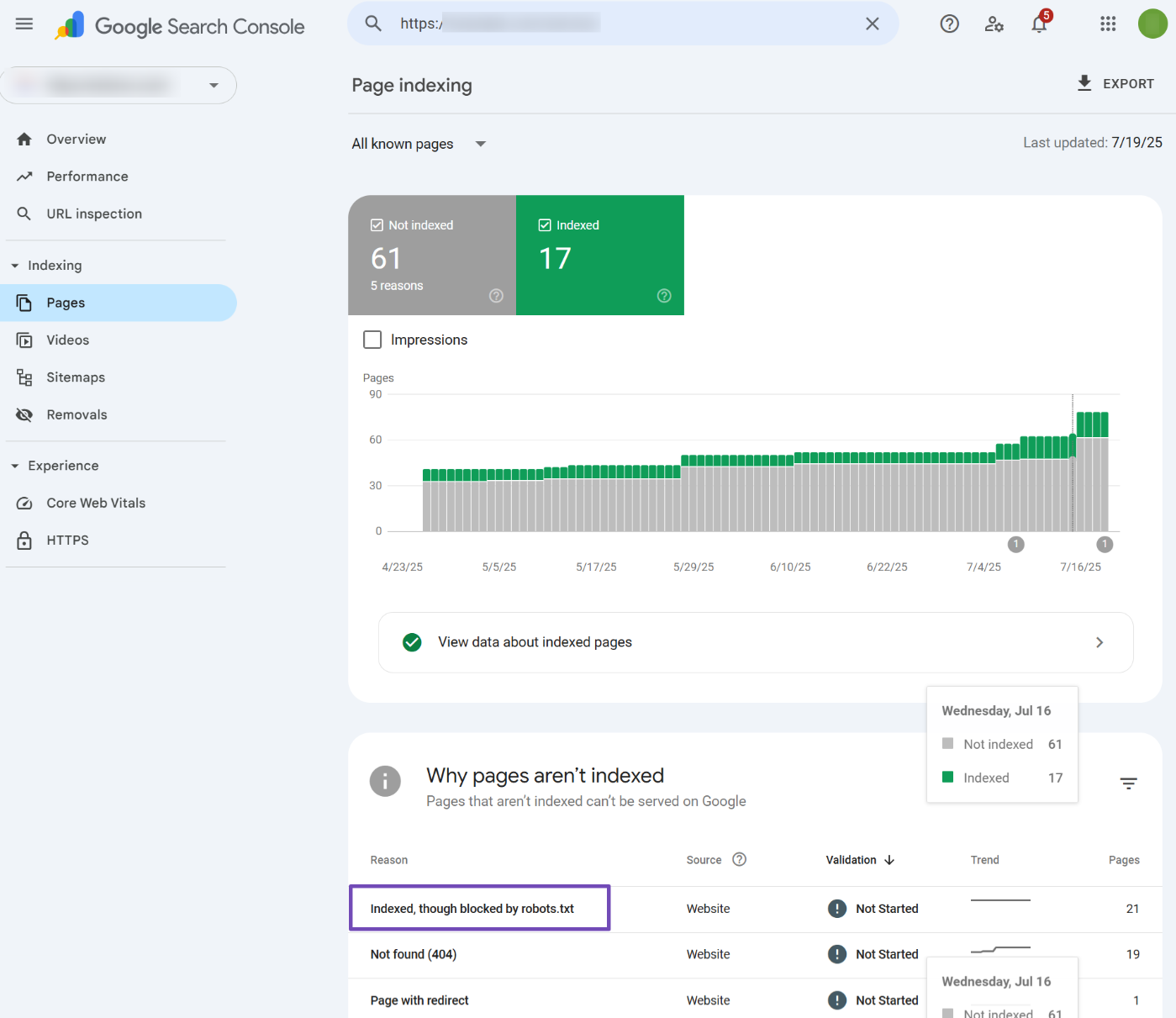
Table of Contents
1 What Does the Error ‘Indexed, Though Blocked by Robots.txt’ Mean?
The error simply means,
- Google has found your page and indexed it in search results.
- But then, it has also found a rule in robots.txt that instructs to ignore the page from crawling.
Now that Google is confused about whether to index the page or not, it simply throws a warning in Google Search Console. So that you can look into this and choose a plan of action.
When you’ve blocked the page with the intention of preventing the page from getting indexed, you need to be aware that — although Google respects the robots.txt in most cases, that alone cannot prevent the page from getting indexed. There could be a multitude of reasons, like an external site linking to your blocked page and eventually leading Google to index the page with the little information available.
On the other hand, if the page is supposed to be indexed but accidentally got blocked by robots.txt, then you should unblock the page from robots.txt to ensure Google’s crawlers are able to access the page.
Now that you get the basic ideology behind this warning, the practical causes behind this could be plenty, considering the CMS and the technical implementation. Hence, we will go through a comprehensive way to debug and fix this warning in this article.
2 Export the Report from Google Search Console
For small websites, you might have only a handful of URLs under this warning. However, most complex websites and eCommerce sites are bound to have hundreds or even thousands of URLs. While it is not feasible to use GSC to go through all the links, you can export the report from Google Search Console and open it with a spreadsheet editor.
To export, simply click the warning that would be available under the Google Search Console Dashboard → Pages → Why pages aren’t indexed section.
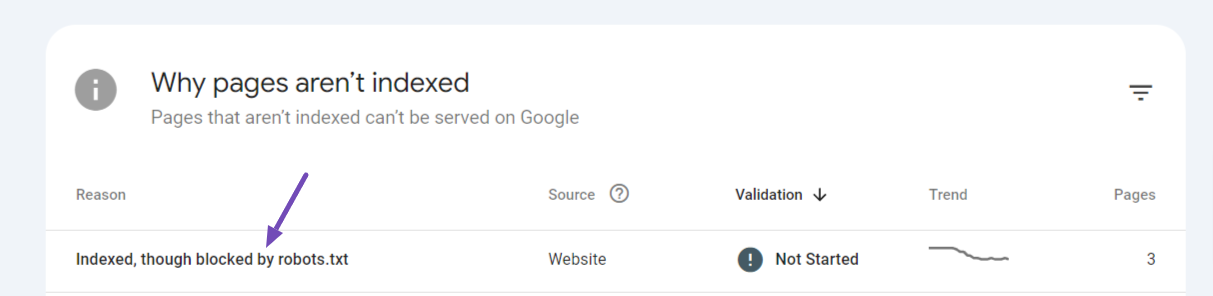
On the next page, you’ll be able to export all the URLs pertaining to this warning by clicking the Export option available in the top-right corner. From the list of export options, you can choose to download and open the file with a spreadsheet editor of your choice.
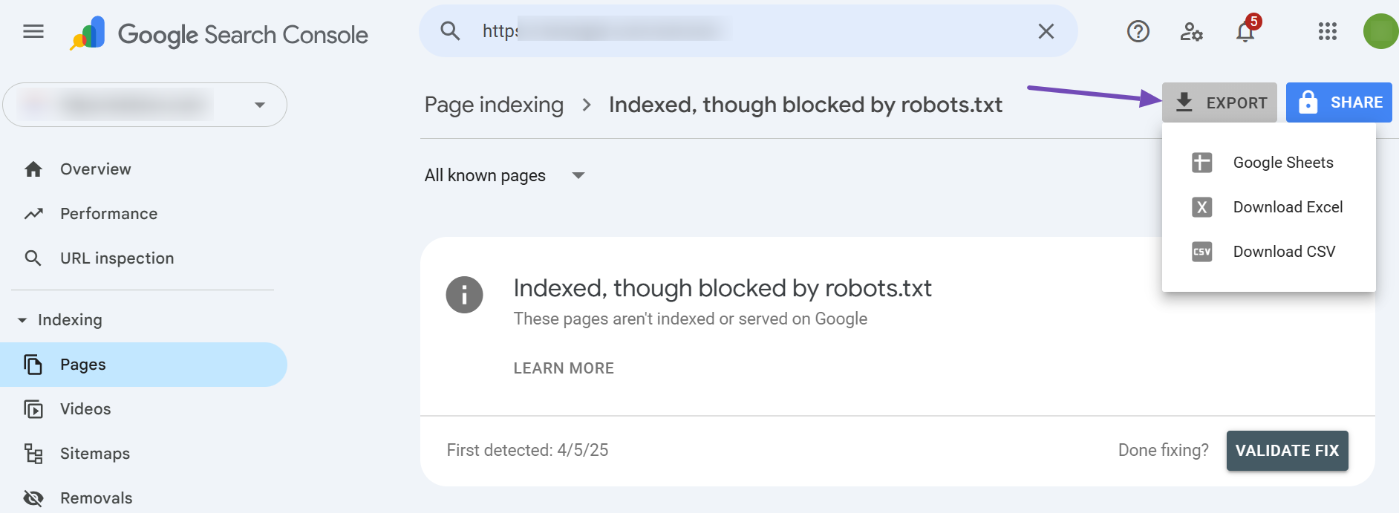
Now that you’ve exported the URLs, the first thing to determine from looking at them is whether the page should be indexed or not. The course of action will only depend on your answer.
3 Pages to Be Indexed
If you determine that the page is supposed to be indexed, you should test your robots.txt and identify any rule preventing Googlebot from crawling it.
To debug your robots.txt file, follow the steps outlined below exactly.
3.1 Open robots.txt Tester
At first, head over to the robots.txt Tester. Here is what it would look like.
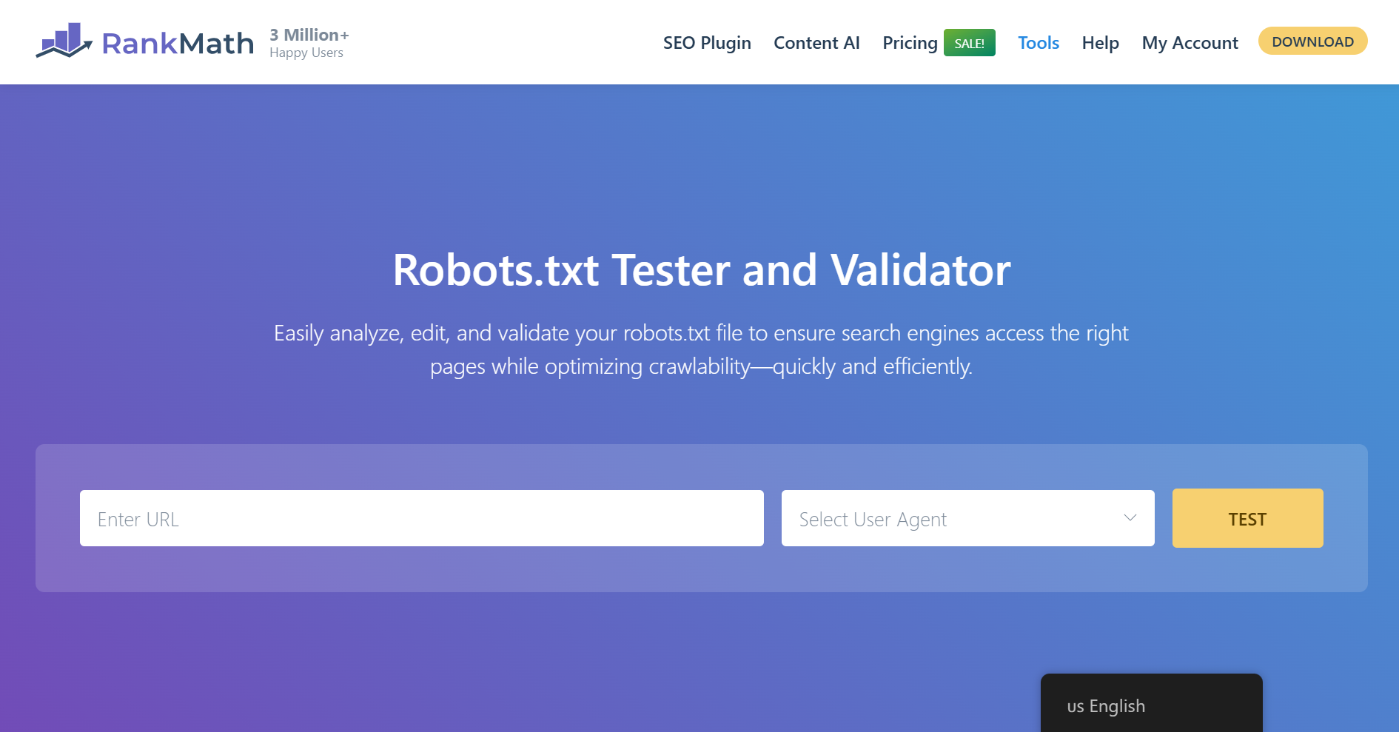
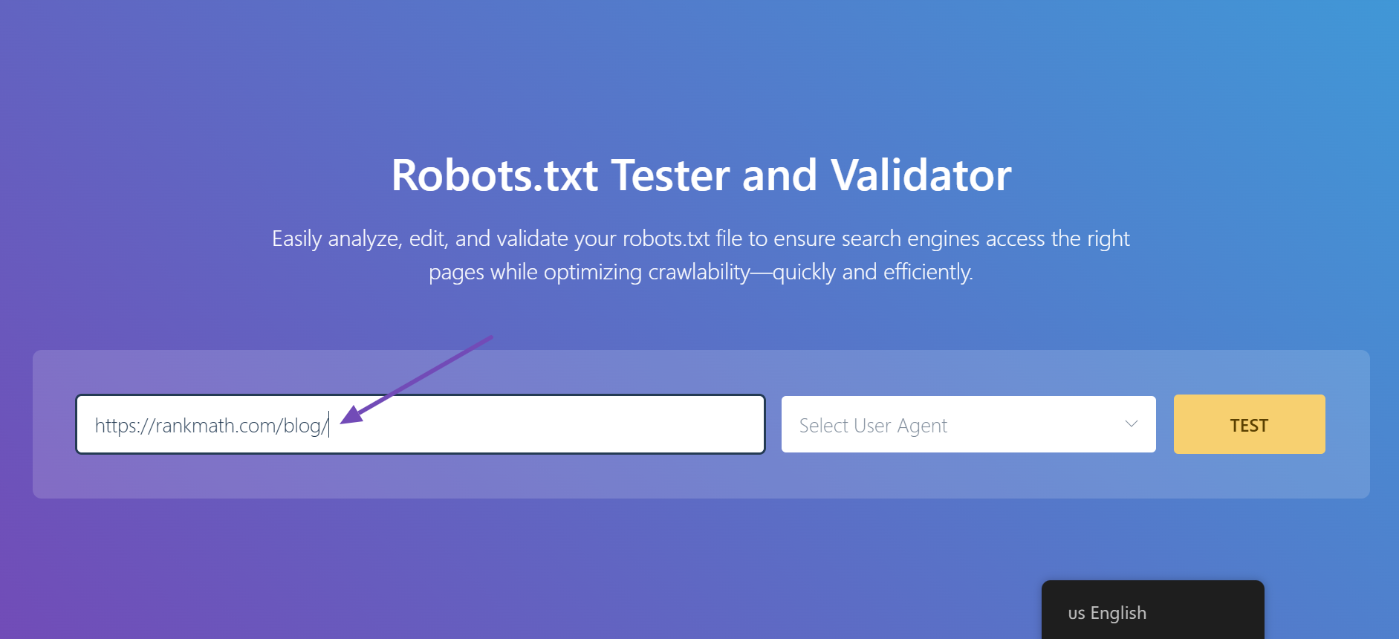
3.2 Enter the URL of Your Site
Then, you will find an option to enter a URL from your website for testing. Here, you will add a URL from the spreadsheet we downloaded earlier.
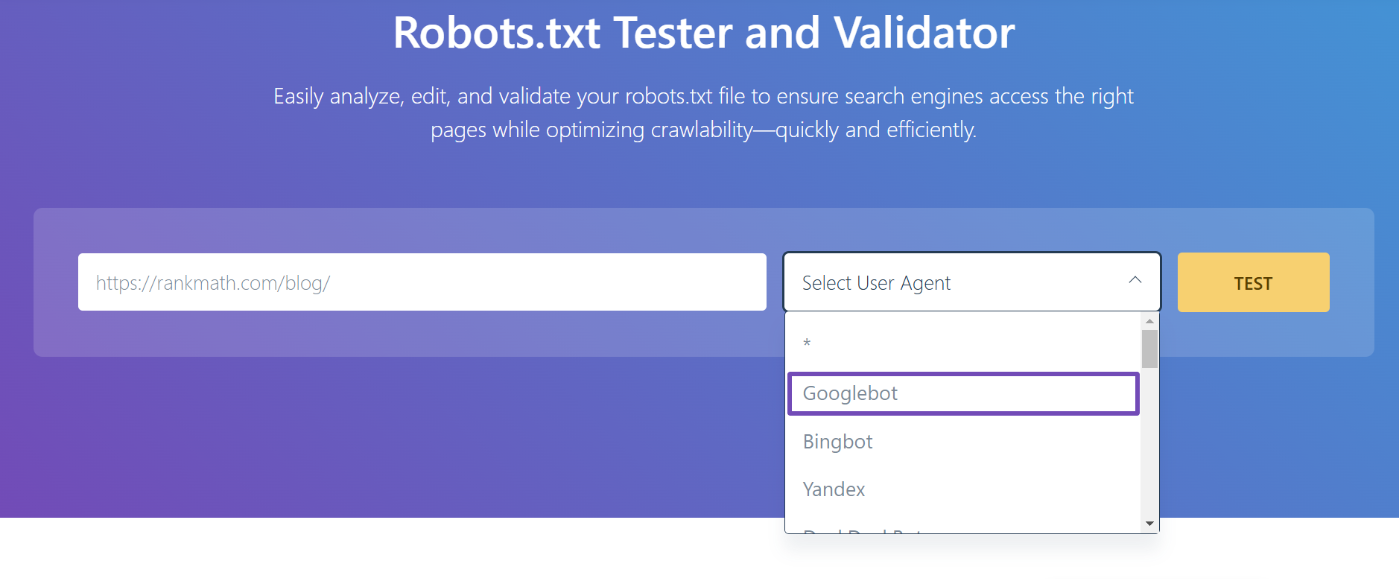
3.3 Select the User-Agent
Next, you will see the dropdown arrow. Click on it, and select the user agent you want to simulate (Googlebot, in our case).
3.4 Validate Robots.txt
Finally, click the TEST button.
The crawler will instantly validate if it has access to the URL based on the robots.txt configuration and accordingly process the test.
The code editor available at the center of the screen will also highlight the unclear rule in your robots.txt, as shown below.
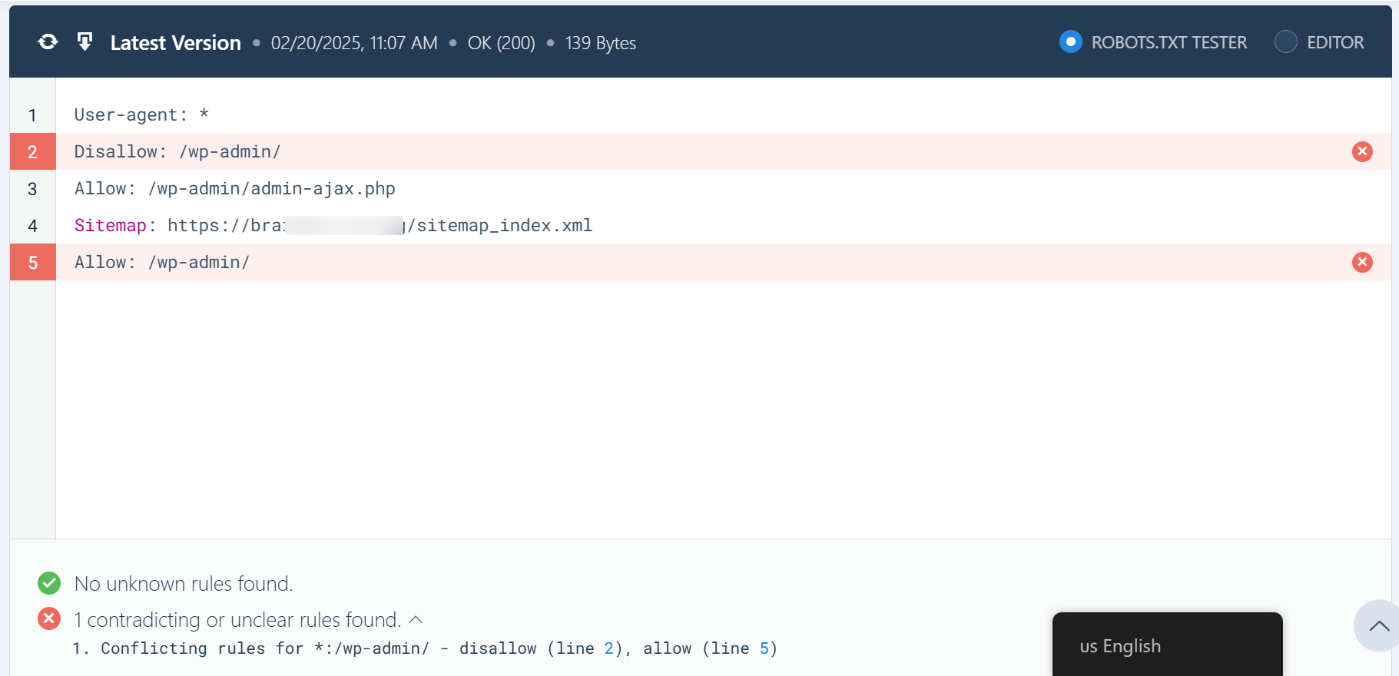
3.5 Edit & Debug
If the robots.txt Tester finds any rule preventing access, you can try editing the rule right inside the code editor and then run through the test once again.
You can also refer to our dedicated knowledgebase article on robots.txt to learn more about the accepted rules, which would be helpful in editing the rules here.
If you happen to fix the rule, then it’s great. But please note that this is a debugging tool, and any changes you make here will not be reflected on your website’s robots.txt unless you copy & paste the contents to your website’s robots.txt.
If you face any difficulties editing robots.txt, please contact support.
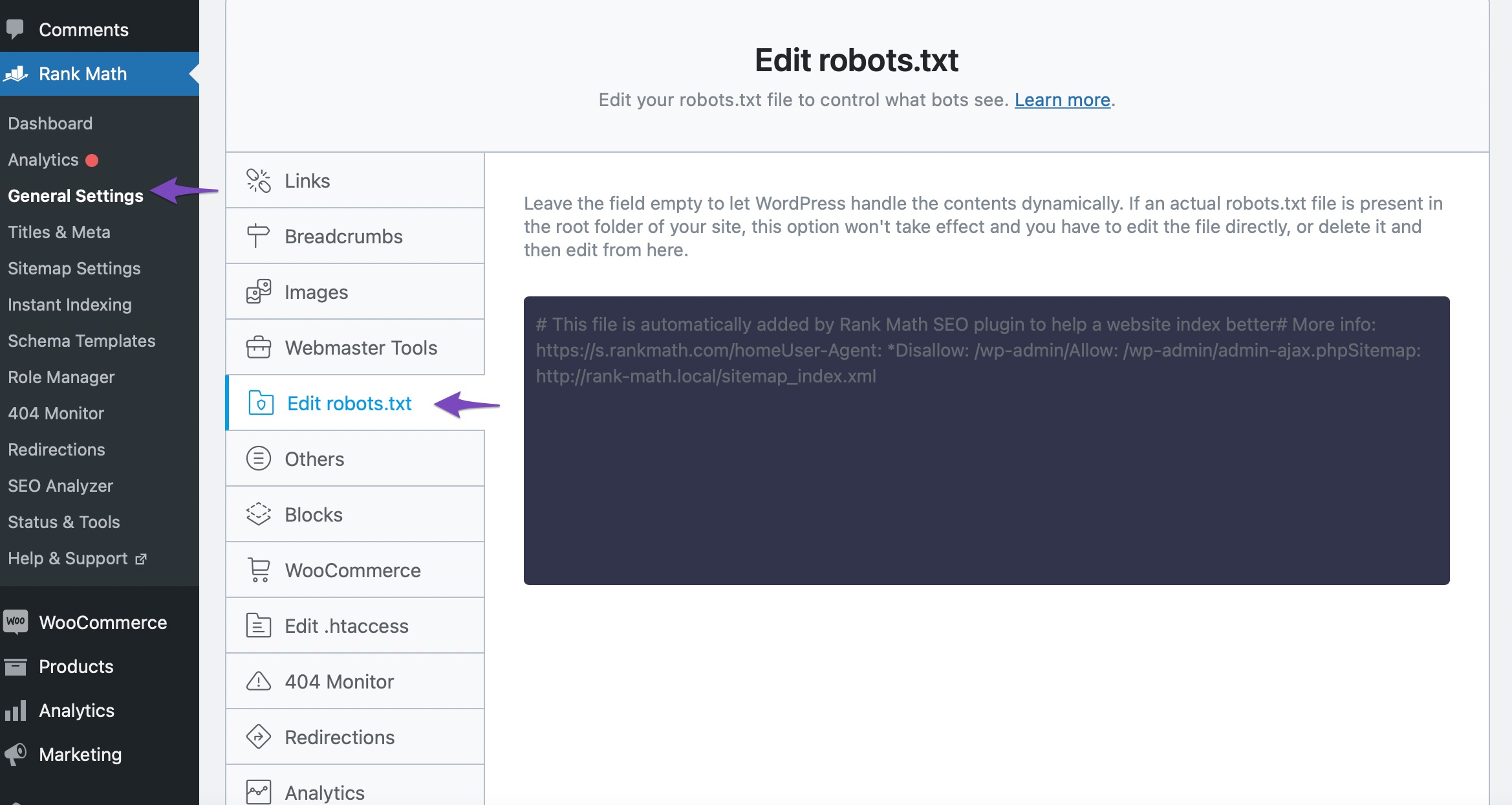
3.6 Export Robots.txt
So to add the modified rules in your robots.txt, head over to Rank Math SEO → General Settings → Edit robots.txt inside your WordPress admin area. If this option isn’t available for you, then ensure you’re using the Advanced Mode in Rank Math.
In the code editor that is available in the middle of your screen, paste the code you’ve copied from the robots.txt. Tester and then click the Save Changes button to reflect the changes.
4 Pages Not to Be Indexed
Well, if you determine the page is not supposed to be indexed, but Google has indexed it, then it could be one of the reasons we’ve discussed below.
4.1 Noindex Pages Blocked Through Robots.txt
When a page should not be indexed in search results, it should be indicated by a Robots Meta directive and not through a robots.txt rule.
A robots.txt file only contains instructions for crawling. Remember, crawling and indexing are two separate processes.
Preventing a page from being crawled ≠ Preventing a page from being indexed
So, to prevent a page from getting indexed, you can add a No Index Robots Meta using Rank Math.
But then, if you add a No Index Robots Meta and simultaneously block the search engine from crawling these URLs, technically, you’re not allowing Googlebot to crawl and know the page has a No Index Robots Meta.
Ideally, you should allow Googlebot to crawl through these pages, and based on the No Index Robots Meta, Google will drop the page from the index.
Note: Use robots.txt only for blocking files (like images, PDFs, feeds, etc.) where it isn’t possible to add a No Index Robots Meta.
4.2 External Links to Blocked Pages
Pages that you have disallowed through robots.txt might have links from external sites. Then, Googlebot will eventually try to index the page.
Since you’ve disallowed bots from crawling the page, Google will index it using the limited information available from the linked page.
To resolve this issue, you might consider reaching out to the external site and requesting to change the link to a more relevant URL on your website.
5 Conclusion — Validate Fix in Google Search Console
Once you’ve fixed the issues with the URLs, head back to the Google Search Console warning and then click the Validate Fix button. Now Google will recrawl these URLs and close the issue if the error is resolved.
And, that’s it! We hope the article helped you fix the error. If you still have absolutely any questions, please feel free to reach our support team directly from here, and we’re always here to help.