Offering PDFs (ebooks, guides, or anything else) can be great sources of lead magnets for building your audience. But that said, you wouldn’t want these valuable resources to be available through Google search for people to find them easily, against downloading them through your forms.
And the same goes for websites in other segments; documents stored in PDF shouldn’t be available in search results unless otherwise, you intend to do.
While we are familiar with preventing your pages from getting indexed in search results using a Robots Meta tag, the same approach will not work for media files and PDF files.
So in this knowledgebase article, we will discuss about preventing your PDF files from showing up in search results.
Table Of Contents
1 Why Noindex Robots Meta Directive Cannot Be Added to PDF Files?
The Robots Meta tag is added to the head of the page’s HTML code. With Rank Math, you can easily add it to your posts, pages, archive pages, and even your attachment pages because they’re all HTML.
But, PDF is not an HTML file and does not contain any HTML code; hence you cannot add a NoIndex Robots Meta tag to it.
If that’s even possible by any means — when your PDF files are accessed, they are not served through WordPress but directly by your server, and your WordPress plugins would not have control over it.
Hence, Rank Math (or any other SEO plugin) cannot add a Robots Meta directive to a PDF file.
But with that said, if your PDF files are already indexed in search results, or you want to prevent your PDF files from being crawled, the following methods will help you to do so.
2 How to Prevent PDF Files from Being Crawled?
2.1 Raise a Search Removal Request
Raising a removal request in Google Search Console is perhaps the quickest way to get your PDF files dropped from the index, and to raise a request, follow the exact steps we’ve discussed below.
2.1.1 Open Search Console
Head over to Google Search Console and then log in to your account. If you haven’t already connected and verified your website in Google Search Console, then you can let Rank Math do that for you.
Choose the correct property if you’ve multiple accounts connected with your Google Search Console.
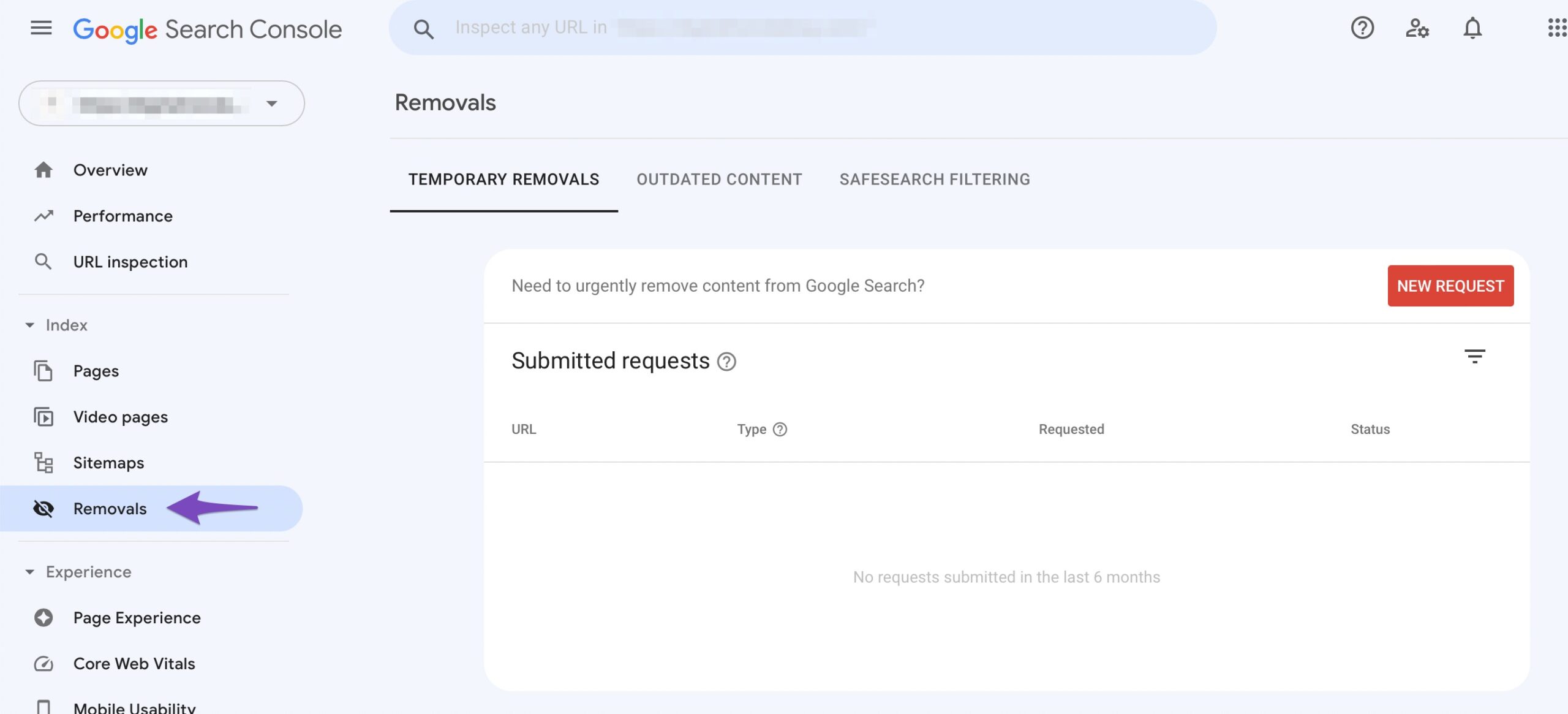
2.1.2 Navigate to Removals Section
From the left sidebar, click the Removals section.
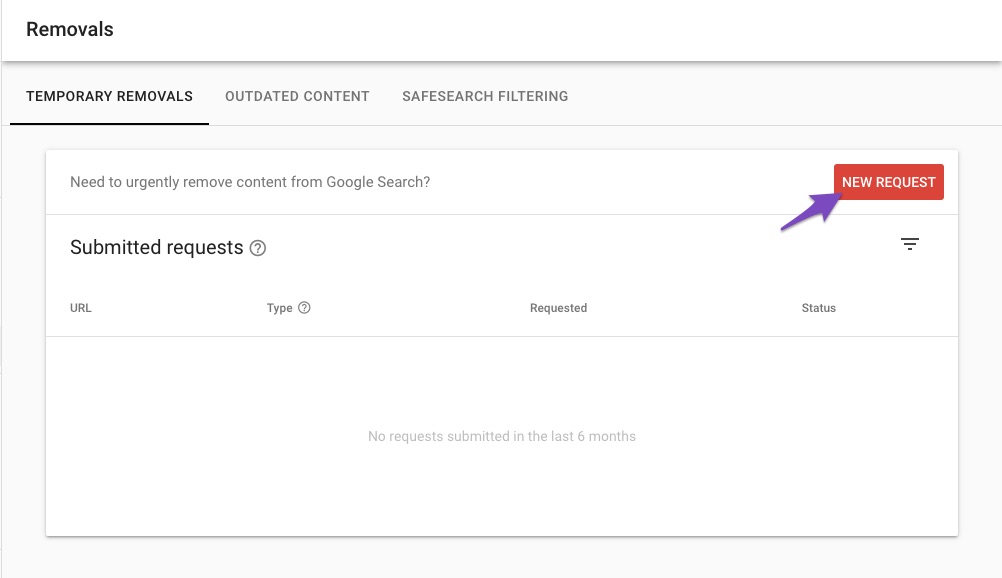
2.1.3 Choose New Request
On the Removals page, click New Request.
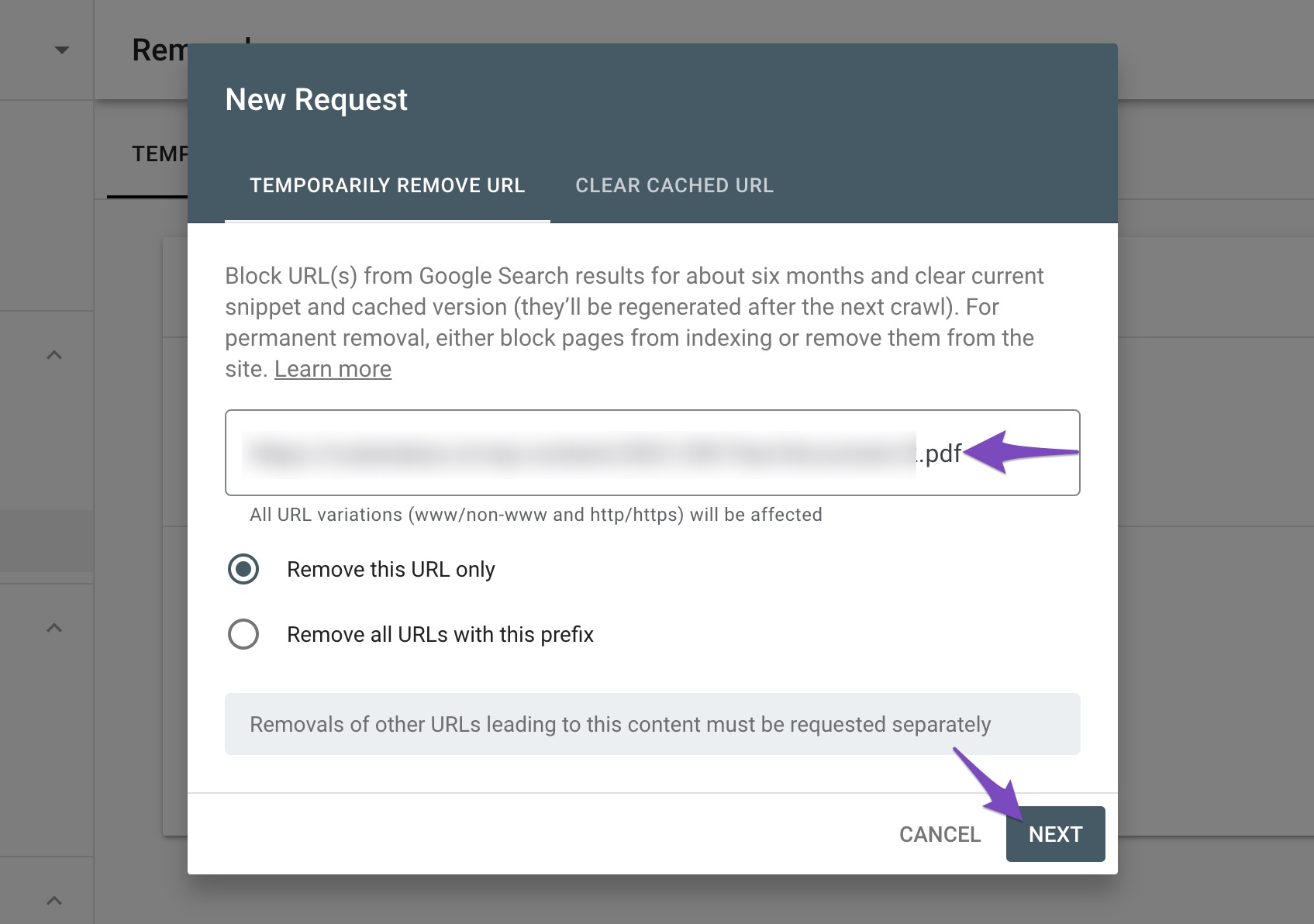
2.1.4 Submit New Request
In the popup that appears on the screen, enter the PDF URL that you want to remove and then click Next.
In the next screen, confirm removing the URL by clicking the Submit Request button.
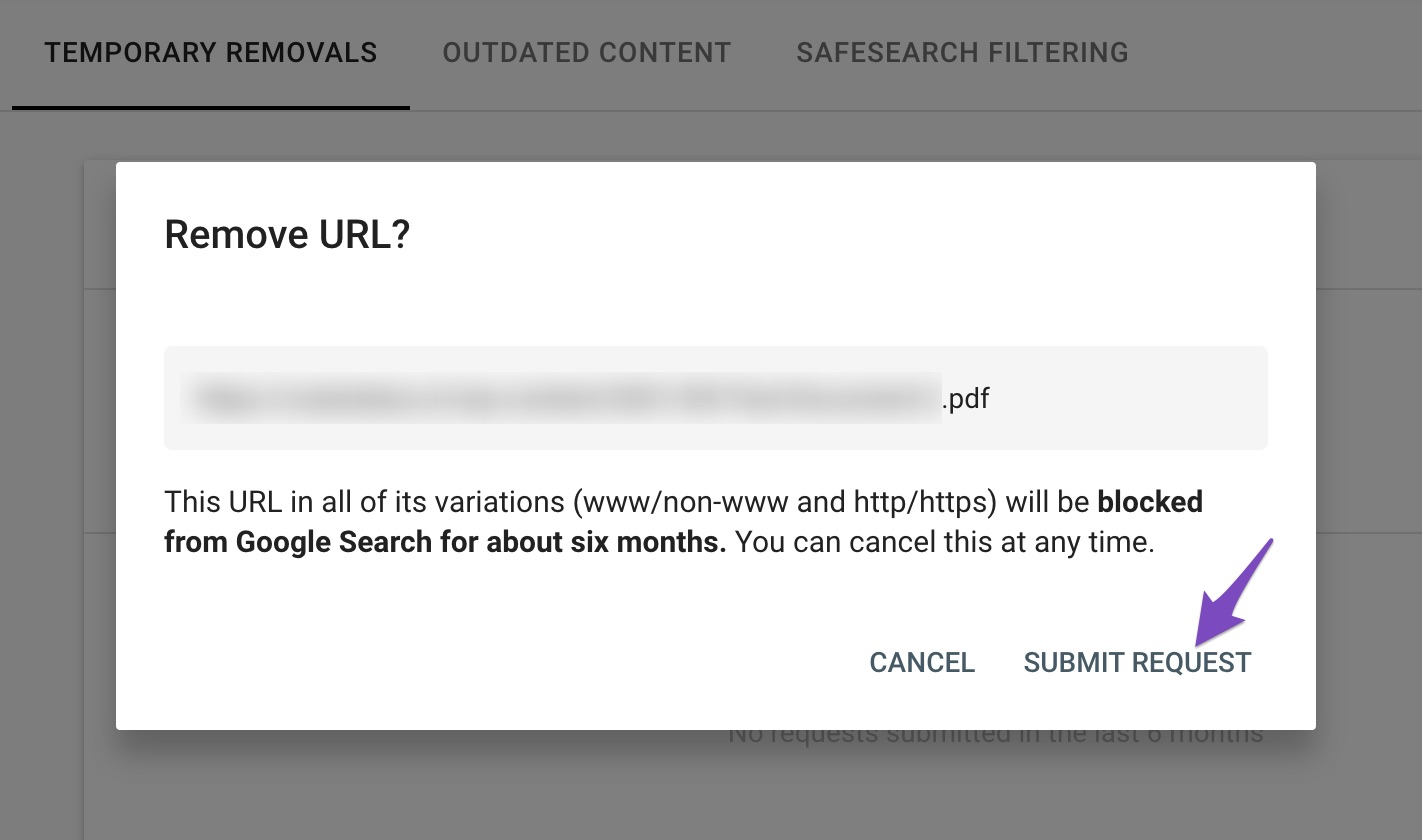
Once the request has been submitted, you can check the removal status in the Google Search Console.
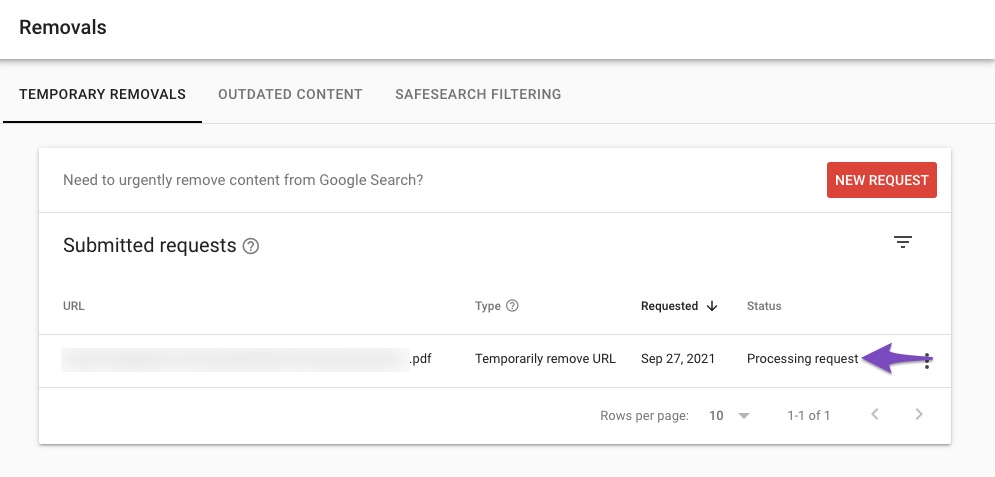
Note: This removal from the search index is only temporary for a set time period. As Google states, the content will not be indexed for six months. But to keep this PDF permanently out of Google’s search index, you’d need to block search engines from crawling the PDF using robots.txt.
2.2 Disallow PDF Files Using robots.txt
By using robots.txt, you can prevent your PDF file from being crawled. However, this will only prevent your page from being crawled and not indexing.
Only when someone links to your PDF file from an external site will search engines go ahead and index your file. Unless someone explicitly links, Google will not crawl your PDF and index your file. Now, let’s look at how to prevent your PDF from being crawled using robots.txt.
2.2.1 Navigate to Your Robots.txt
Head over to WordPress Dashboard → Rank Math SEO → General Settings → Edit Robots.txt. If the Edit Robots.txt option isn’t available, then ensure you’re using the Advanced Mode in Rank Math.
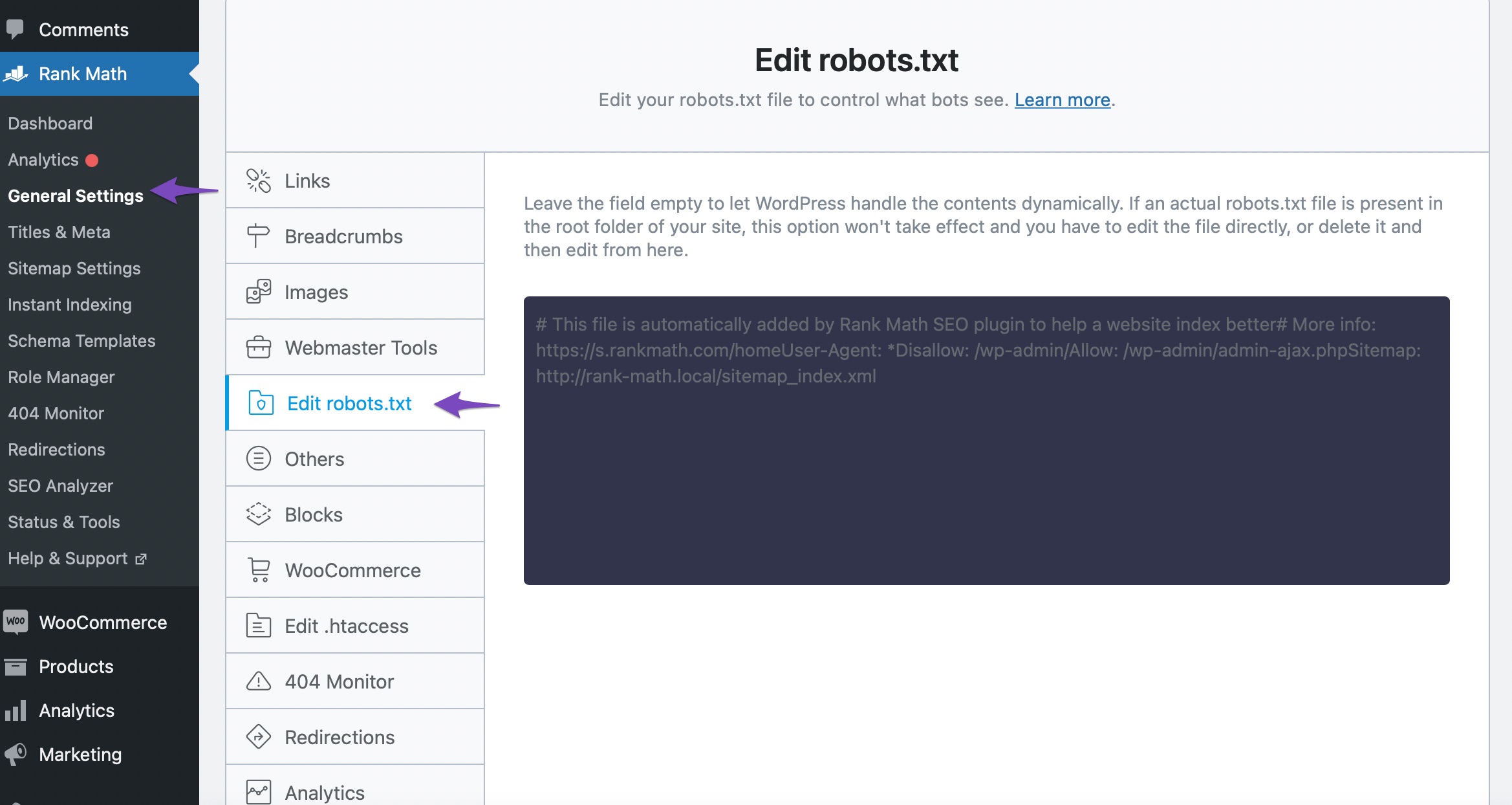
2.2.2 Edit Robots.txt
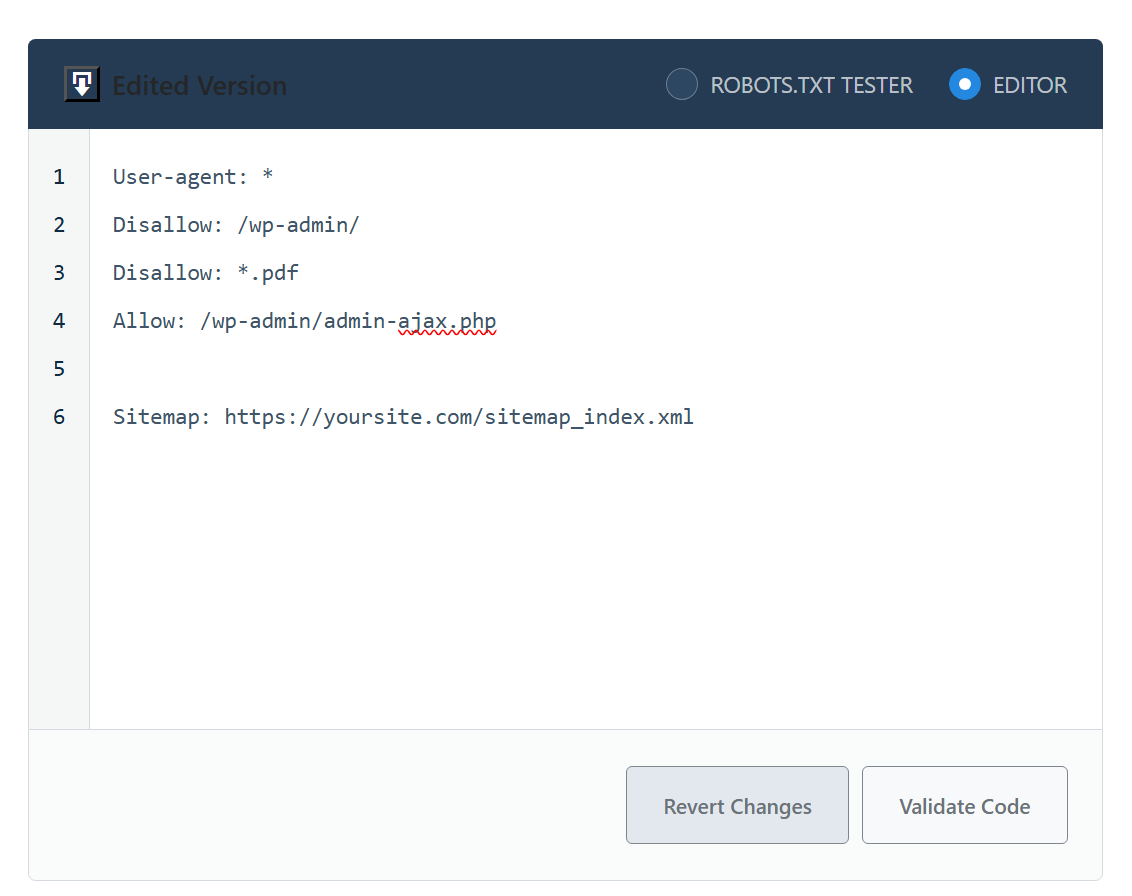
And then, copy and paste the following code into the code editor. Make sure to replace yoursite.com with your domain name. The Disallow: *.pdf rule added here will instruct search engines not to crawl PDF files.
User-agent: *
Disallow: /wp-admin/
Disallow: *.pdf
Allow: /wp-admin/admin-ajax.php
Sitemap: https://yoursite.com/sitemap_index.xml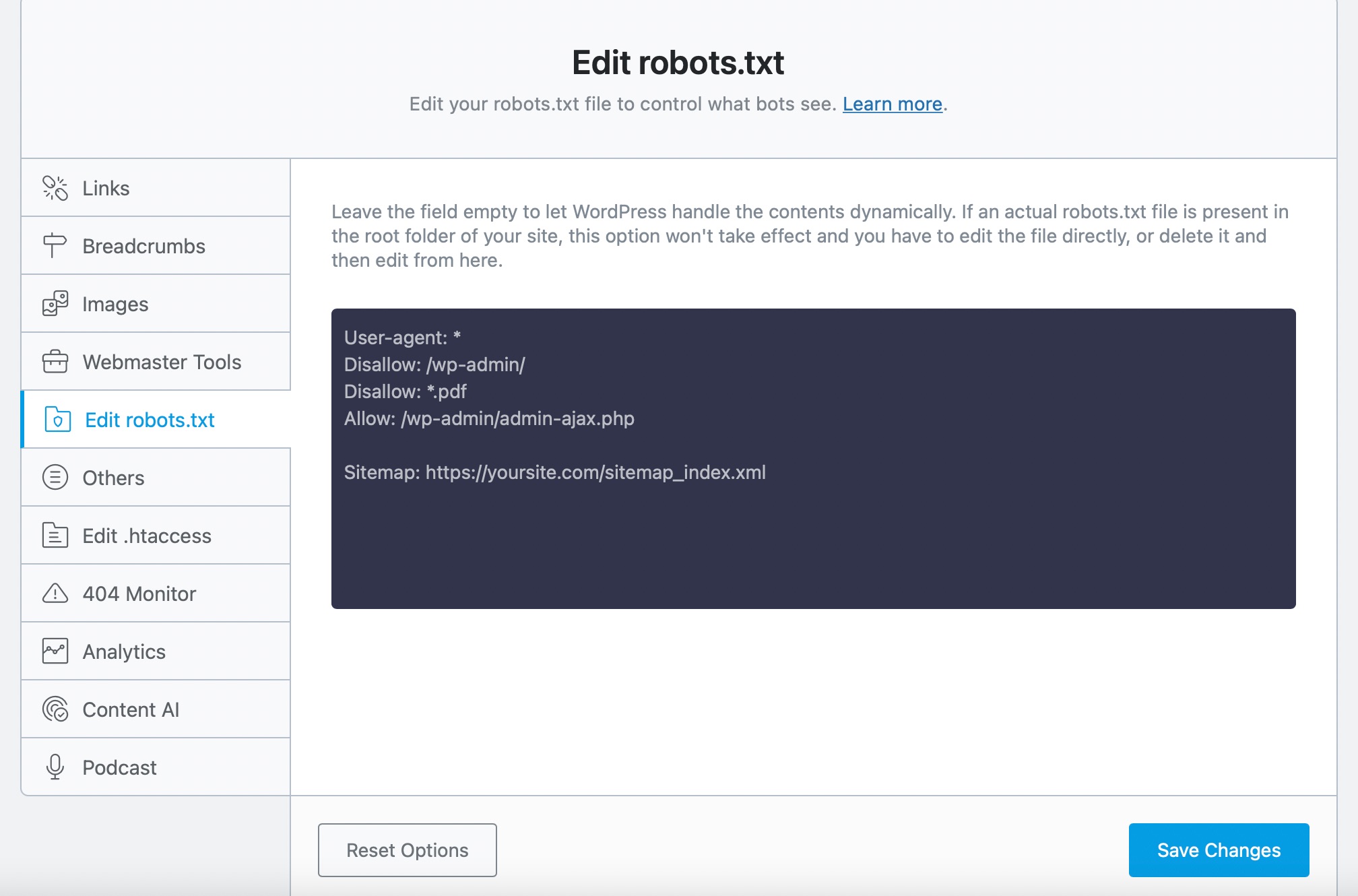
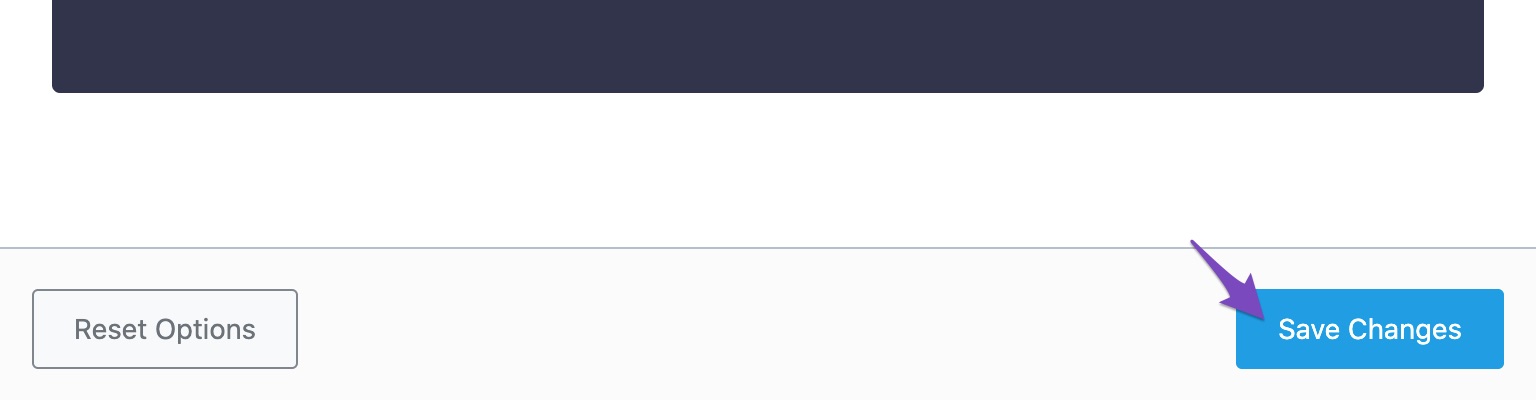
If you’re using the PRO version, ensure that you select the EDITOR option before adding the rule to your robots.txt file, as shown below. Once you’re done, you can use the Validate Code button to return to the preview.
2.2.3 Save Changes
Now, click the Save Changes button at the bottom of the screen to reflect the changes.
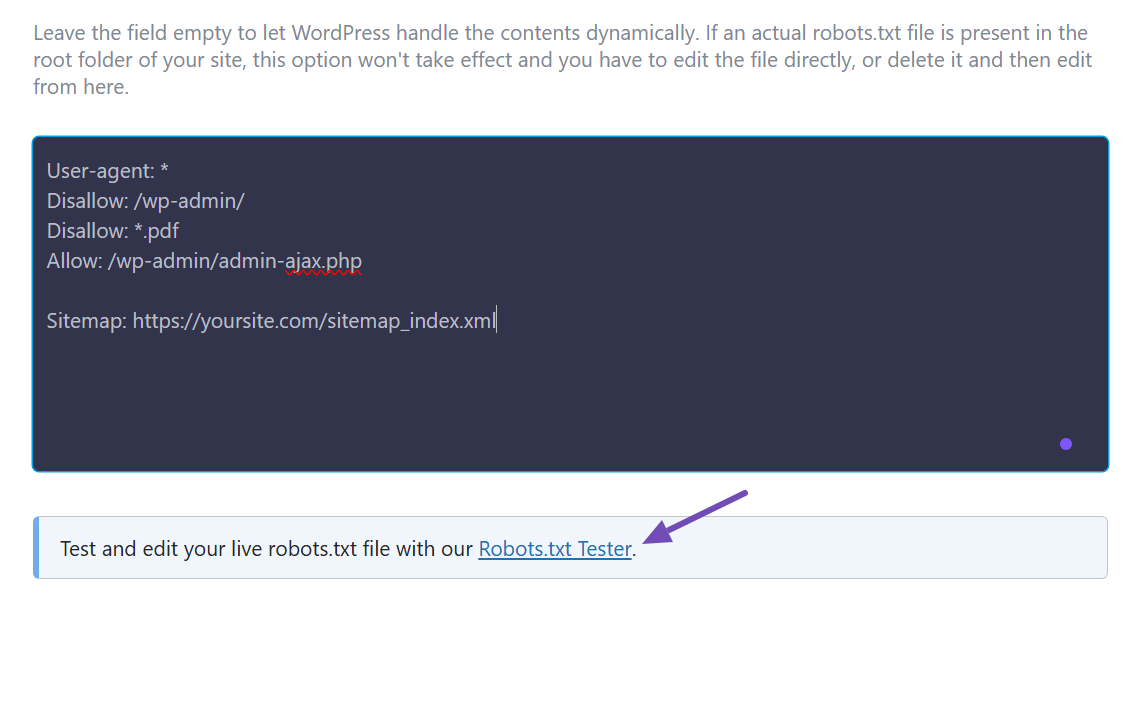
You can test and confirm using our robots.txt Tester by clicking the link below your file to see if Googlebot can crawl and access your PDF file, as shown in the example below.
2.3 Disallow PDF Files Using X-Robots-Tag
X-robots-tag is another method to prevent non-HTML files like PDFs from indexing. It is more complicated rather than the Robot Meta tag.
To prevent PDF files from using x-robots-tag, you’ll need to modify your website’s htaccess file, header.php, or require server-level modification.
If you’re using an Apache server, then add the following x-robots-tag in your website’s httpd.config file or htaccess file.
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, follow"
</Files>And for the Nginx server, add the following x-robots-tag.
location ~* \.pdf$
{
add_header X-Robots-Tag "noindex, follow";
}Note: Make sure to check Google’s guidelines on x-robots-tag before making any modification to your website’s file.
And that’s it! We hope the above methods helped you prevent your PDF files from being crawled and get them dropped out of the search index. If you still have absolutely any questions about indexing your content, please feel free to reach our support team directly from here, and we’re always here to help.