One of the most important things you can do to ensure your website’s success is to create and maintain a well-optimized robots.txt file.
A robots.txt file tells which pages on your website, search engines like Google should crawl and which pages they should ignore. This is important because you don’t want every single page on your website to be indexed – especially if some of those pages are low-quality or duplicate content.
If you have a WordPress multisite, then you need to be especially careful about your robots.txt file. This is because a WordPress multisite can have hundreds or even thousands of websites, all with their own individual settings.
The good news is that Rank Math makes it easy to manage your robots.txt file on a WordPress multisite. In this knowledge base article, we’ll help you create the best robots.txt file rules for multisite using Rank Math SEO.
1 Technical Robots.txt Syntax
First, let’s take a look at what you need to include in your robots.txt file.
- User-agent: Each search engine identifies itself by a user-agent string which is usually hidden from the user but can be seen in web server logs. User agents are used to distinguish which crawler is accessing the page and can be used to identify the search engine. For example, Google’s robots are identified as Googlebot, Yahoo’s robots are identified as Slurp, and Bing’s robots are known as BingBot.
- Disallow: You can instruct search engines not to access or crawl certain files, pages, or sections of your website by using a Disallow directive. The Disallow directive is used to prevent direct access to a file, folder, or resource on a web server.
- Allow: The Allow directive allows a request if the server has the specified file, directory, or URL. In other words, it overrides the Disallow directive. It is supported by both Google and Bing. The Allow and Disallow directives together let you control what web crawlers like Googlebot can see and access your website. You can even set up rules for particular pages, so the crawler will only see a set of pages in a certain folder and not anything else.
- Sitemap: You can use the command to call out the location of any XML sitemap(s) associated with this URL. This is useful when submitting a site for SEO purposes. Google and Bing are the major search engines that support sitemaps.
- Crawl-Delay: It’s an unfortunate truth of web hosting that, while the majority of the time your site is working fine, you’ll inevitably come across a situation where there is an issue with your server, and it may need some work to get things back to the way they were. The Crawl-delay directive is an unofficial method to avoid overloading a web server with too many requests.
Now that you know what to include in your robots.txt file, let’s take a look at how to create the best rules for your WordPress multisite using Rank Math. Before we get started, you’ll need to make sure that you have the latest version of Rank Math installed and activated on your WordPress site.
Note: If you want to find out how to add robots.txt for a single site, there’s an article on this KB that explains how to set up robots.txt on a single site.
2 How to Set Robots.txt for Multisite?
When you install Rank Math on a multisite or multiple domains, you should install it on the network and only use it on individual websites.
But please note that the robots.txt can only be modified on the main site of the network, and all others will inherit the settings from the main site.
This is because the sites on the network don’t have an actual file structure that could support these types of files, and this is a limitation of the multisite functionality.
Usually, the robots.txt file should be in the top directory of your web server. Even if it’s a sub-directory installation, the robots.txt should be accessible from the main URL.
But, Rank Math uses the robots_txt filter to add the content. If the robots.txt file exists on the server then, Rank Math automatically disables the option to edit or modify the robots.txt file. This is done to prevent the user from overwriting the file.
3 How You Can Handle Robots.txt on a Multisite Using Rank Math?
If you are using a WordPress multisite, the robots.txt file is a bit more complicated, and you’ll need to take care of it while editing it. The best way to edit your robots.txt file on a WordPress multisite is to use the network settings to determine which rules apply to which sites on your network.
Note: We assumed that you already installed Rank Math on your WordPress multisite, if not we recommend reading this article Installing Rank Math on a Multisite Environment.
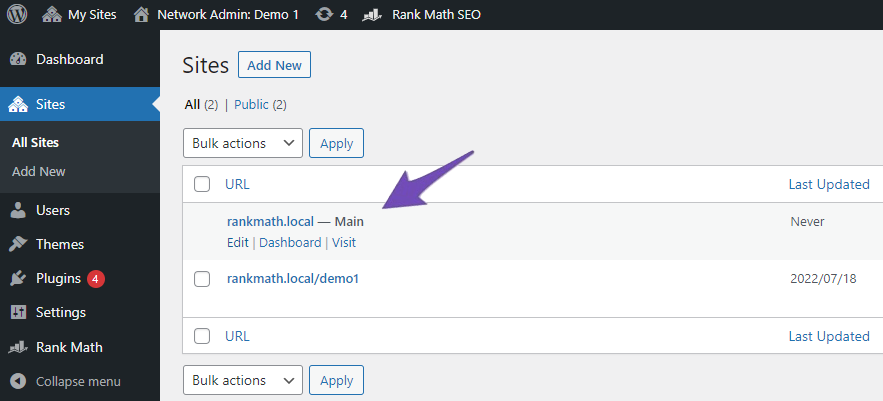
In order to do this, go to Network Admin → Sites.
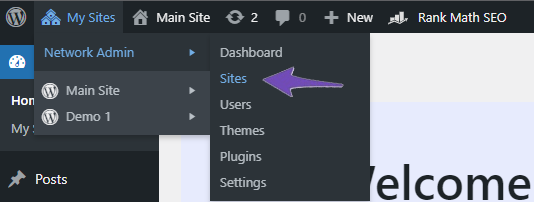
Next, click on the Dashboard tab for the site for which you want to add robots.txt rules.
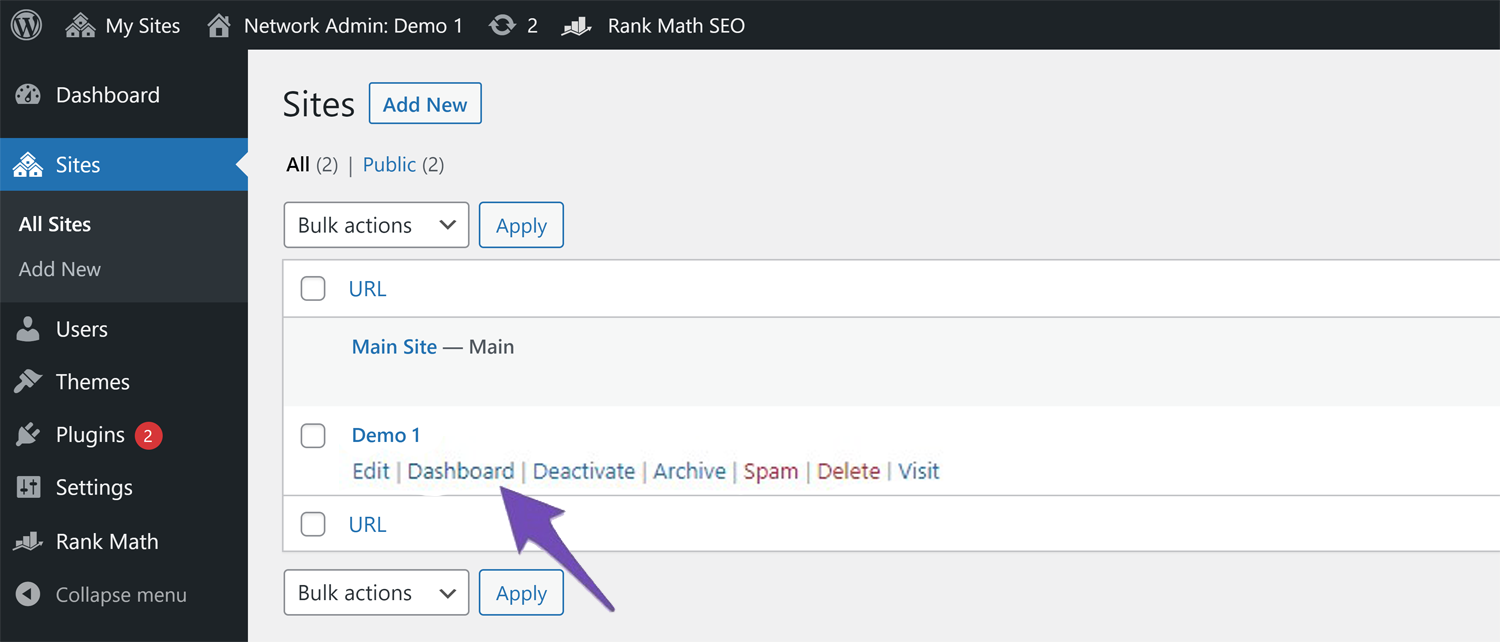
Once you are on the site’s dashboard, navigate Rank Math SEO → General Settings. Here, you will be able to edit your robots.txt file and add the necessary rules.
Ensure that you save your changes before you leave the page. Repeat these steps for each site on your network where you want to add robots.txt rules.
4 Examples of Robots.txt Rule
There are only a few rules that are allowed in robots.txt, and they should be used right away. If you make a small error, you might lose all the hard-earned traffic and may lose the ranking position. Here are some examples of robots.txt rules:
4.1 Allow Entire Domain & Block a Specific Subdirectory
This will allow search engine bots to access every page on your website, except for the pages that are located in the /subdirectory/ folder. If you have a multisite network and want to block access to a specific subsite, you can use this code:
User-agent: *
Disallow: /subsite/
Sitemap: https://www.example.com/sitemap.xmlIn the above example, the * character is a wildcard that allows all bots to access the website. The Disallow tells the bots not to crawl any pages in the subsite directory. The Sitemap tells the bots where to find your sitemap so they can crawl your website more efficiently.
Be sure to replace the /subsite/ with your desired directory.
4.2 Disallow Crawling Entire Website
This rule prevents all search engine bots from crawling your entire website. The / in the rule represents the root of the website directory and includes all the web pages.
This rule is not recommended for live websites as it blocks search engine bots from crawling and indexing your website.
You can use this rule when your website is in the development stage, where you wouldn’t want the crawlers to access and index the content that is yet to be shown.
User-agent: *
Disallow: /4.3 Disallow Crawling of the Entire Website for a Specific Bot
If you only want to secure your website access from specific web crawlers, you can replace the wildcard in the User-agent with the name of the crawlers, such as Adsbot of Google.
User-agent: AdsBot-Google
Disallow: /Now, blocking the above-mentioned crawler, if you want other search engine bots to crawl your website, then use the following.
User-agent: AdsBot-Google
Disallow: /
User-agent: *
Allow: /4.4 Default Robots.txt in Rank Math
By default, you’ll be able to see the following rules in the robots.txt file editor field of Rank Math.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: yoursite.com/sitemap_index.xmlYou can change or customize this rule according to your needs. But we suggest you keep a copy of this rule before making any changes.
4.5 Disallow Access to Specific Directory
If you want to block access to specific directories on your website, then you can include the relative path of the directory with the disallow rule. The following rule shows you one example where you can block access to the feed pages on your website.
User-agent: *
Disallow: */feed/4.6 Disallow Crawling of Files of a Specific File Type
You can also consider using the following rule to prevent search engine crawlers from accessing or crawling specific file types.
User-agent: *
Disallow: /*.pdf$However, blocking CSS and JS files is not recommended by Google. Because it would prevent the rendering of the page for Google, and this can potentially affect your search rankings.
5 Conclusion
And, that’s it! We hope this KB article has helped you understand how to edit robots.txt rules for multisite or multiple domains. If you still have any questions or are facing any problems while editing the robots.txt rule for a single site or multisite, please don’t hesitate to contact our dedicated support team anytime because we’re available 24/7, 365 days a year. We would be happy to help you anytime.