Google does not index 100% of the pages you submit, and there are various reasons for a page to be excluded from being indexed. If you’ve already verified your website with Google Search Console, you can identify these excluded pages by navigating to the Pages → Not Indexed section inside your Search Console.
![[Solved] Discovered / Crawled - Currently Not Indexed Issue in Google Search Console](https://img.youtube.com/vi/S5hcOZmslBw/maxresdefault.jpg)
This section contains various reasons for pages being excluded, and one among them is, Crawled – currently not indexed. In this knowledgebase article, we’ll understand what this status means and how you can increase your chances of indexing your pages.
1 What Does This Status Mean?
Crawled – currently not indexed means Google has crawled your page but has not indexed it yet. As we already know, Google does not index all the URLs we submit, and finding a certain number of URLs under this status is completely normal. And to make it clear, this isn’t an error but more of a reason why Google has excluded the page(s) from its index.
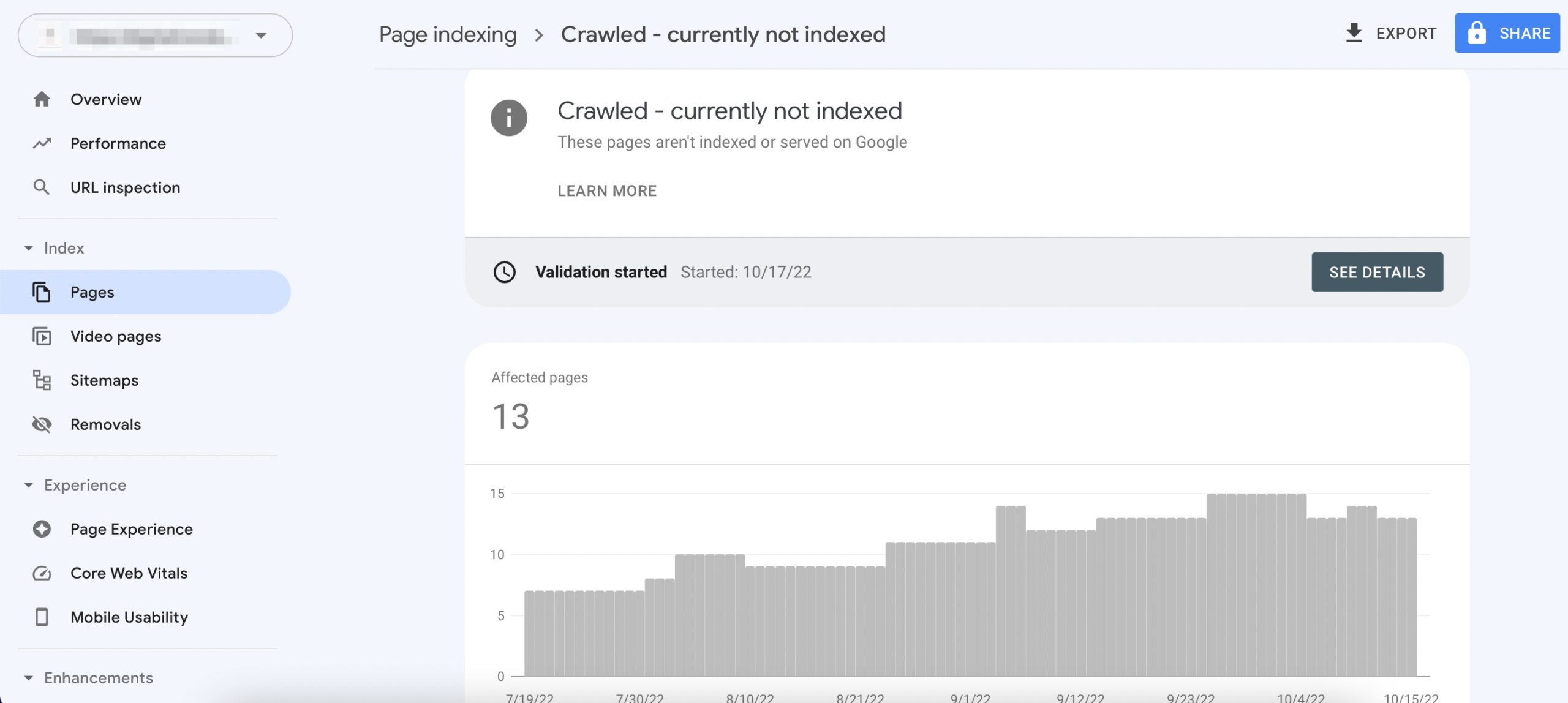
Regardless of how the Search Console reports it, we understand this status seems alarming, as it is important for a page to get indexed before it can rank for keywords & drive organic traffic to your website. So, let’s understand why your pages are grouped under this status.
1.1 Reporting Difference
When you notice a URL being marked as “Crawled – currently not indexed”, you first need to check the page with the URL Inspection Tool.

If the URL Inspection Tool marks the page indexed, it indicates a discrepancy between the reports in the Google Search Console.
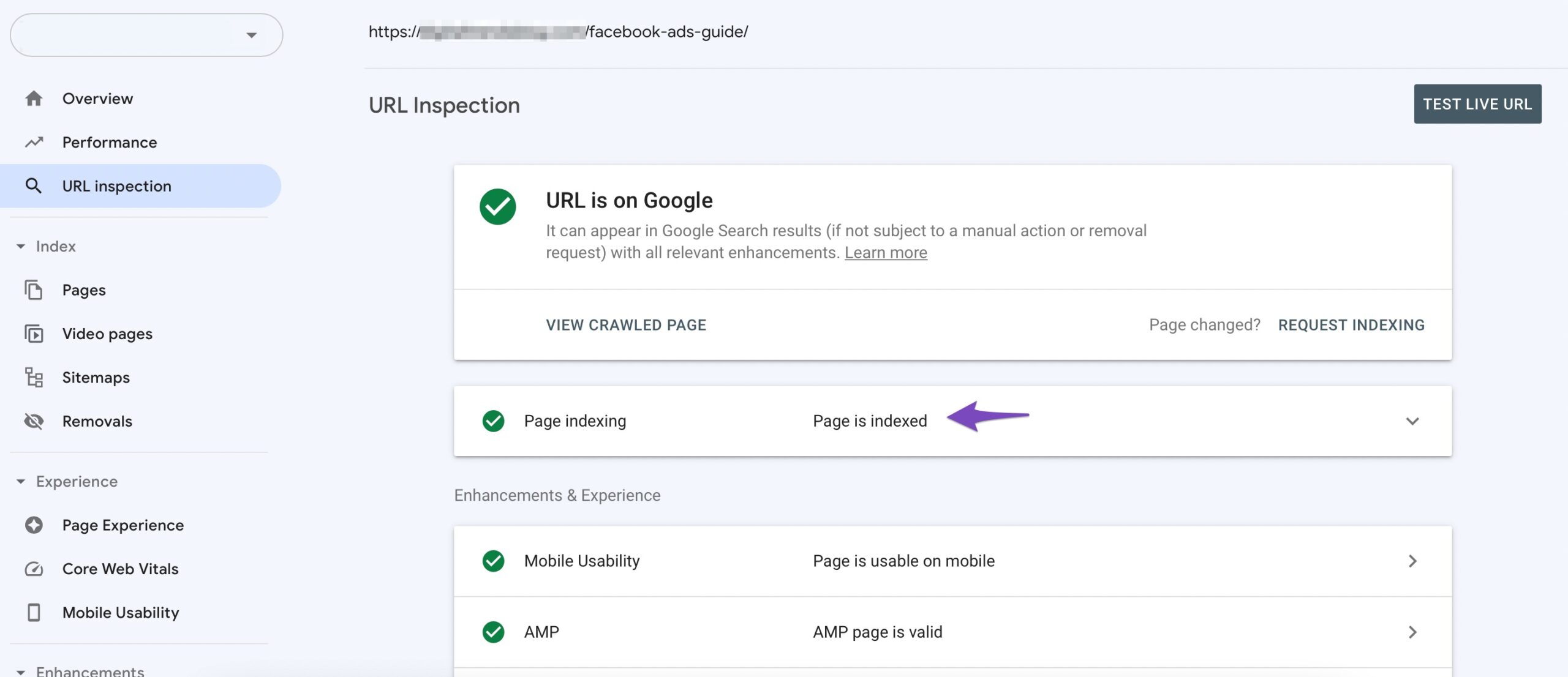
Google has also explained that Page indexing report data is being refreshed at a different rate (usually at a slower rate) compared to their URL Inspection tool. So it is understandable that it takes a few days for the Page indexing report to reflect the actual status of any page.
The URL Inspection tool reflects more recent data and should be considered for checking the page status. Here is what Google has got to say:
Despite the fact that there is a reporting gap in Google Search Console, webmasters have reported pages being indexed a very long ago, still being reported as Crawled – currently not indexed. If you happen to notice the same, it is likely another reporting issue from Google, and we recommend you to open a thread at Google Search Help Community for the experts to have a further look into the issue.
1.2 Site-Wide Quality Issue
As we said, you need to consider the URL Inspection Tool to check the actual status of the page. But, if the URL Inspection Tool also reflects the status as Crawled – currently not indexed, then it is certainly not a reporting issue.
So to dig deeper into this issue, we would recommend you to look into the type of URLs that are being excluded under this status.
If you notice most pages are of the type archives pages, feed pages, and other miscellaneous pages with really thin content, then it is understandable that the page does not provide any value to the users to be indexed in the search results. If that is the case, it is safe to say you can ignore this status.
But if you’re seeing any important pages (having valuable/useful information) on your website being listed here, then as Google’s John Mueller suggests, it is likely an overall site-wide quality issue that has affected your important pages from being indexed.
Further, he recommends improving the structure & overall quality of your website.
You can’t force pages to be indexed — it’s normal that we don’t index all pages on all websites. It’s not an issue with “that page”, it’s more site-wide. Creating a good site structure and making sure the site is of the highest quality possible is essentially the direction.— John Mueller (@JohnMu) June 28, 2021
1.3 Appearance of WebP Images
You might also be confused when WebP images appear in the “Crawled – currently not indexed” report in Google Search Console. It’s important to remember that WebP images are image files, not HTML pages. As such, they don’t get indexed in the same way that webpages do. Google treats them differently because they lack the content and structure that defines a webpage.
If the image URL resembles a webpage link or the file extension is unclear (e.g., .php or none), it may lead to confusion in the indexing process. This can cause Google to categorize these images as “Crawled – currently not indexed.”
However, even though they aren’t indexed in this report, WebP images can still be discovered through Google Image Search. So, if you see this in your Search Console, you can safely ignore it.
2 How to Improve the Overall Site Quality?
Simply put, for a page to be indexed, the page (and website) must pass quality checks. Since Google has not disclosed anything specific they look for while indexing, you must consider evaluating your website against well-known quality factors like,
2.1 Internal Linking Structure
If you’re trying to index an important page, ensure they have internal links from relevant pages on your website. To build internal links, you can set your important pages as pillar content and let Rank Math suggest relevant internal links.
2.2 Duplicate Content
Check if the pages you’re trying to index are duplicated on your website. In case you find any, add a canonical tag from these duplicate pages, pointing to the original content that you want to index.
2.3 Content Audit
At any point in time, a website will have some outdated content. A content audit will help you identify such pages lacking value, and you can improve the page. In cases where it is inappropriate to add more content to the page, you may consider alternatives like,
- Removing the page altogether
- Redirecting to a more relevant page
- Adding noindex meta tag
When you add a noindex meta tag, the content will still remain on your website for your audience, but you’re telling search engines not to consider this for indexing. As confirmed by Google’s John Mueller, site quality is considered only for pages that are set to be indexed.
You can improve the overall site quality by systematically removing low-quality pages from the index. Having said that, site quality isn’t something that changes overnight. It takes a while for Google to pick up the signals, reprocess and reevaluate your overall site quality.
Making significant quality changes across a site takes time to be picked up & reflected in search. These things often take several months to be reprocessed & reevaluated.— John Mueller (@JohnMu) June 16, 2021.
But rest assured, any improvement in the site quality will be rewarded with increased visibility in search results.
3 How to Fix “Crawled- Currently Not Indexed” Error in Google Search Console Using Rank Math
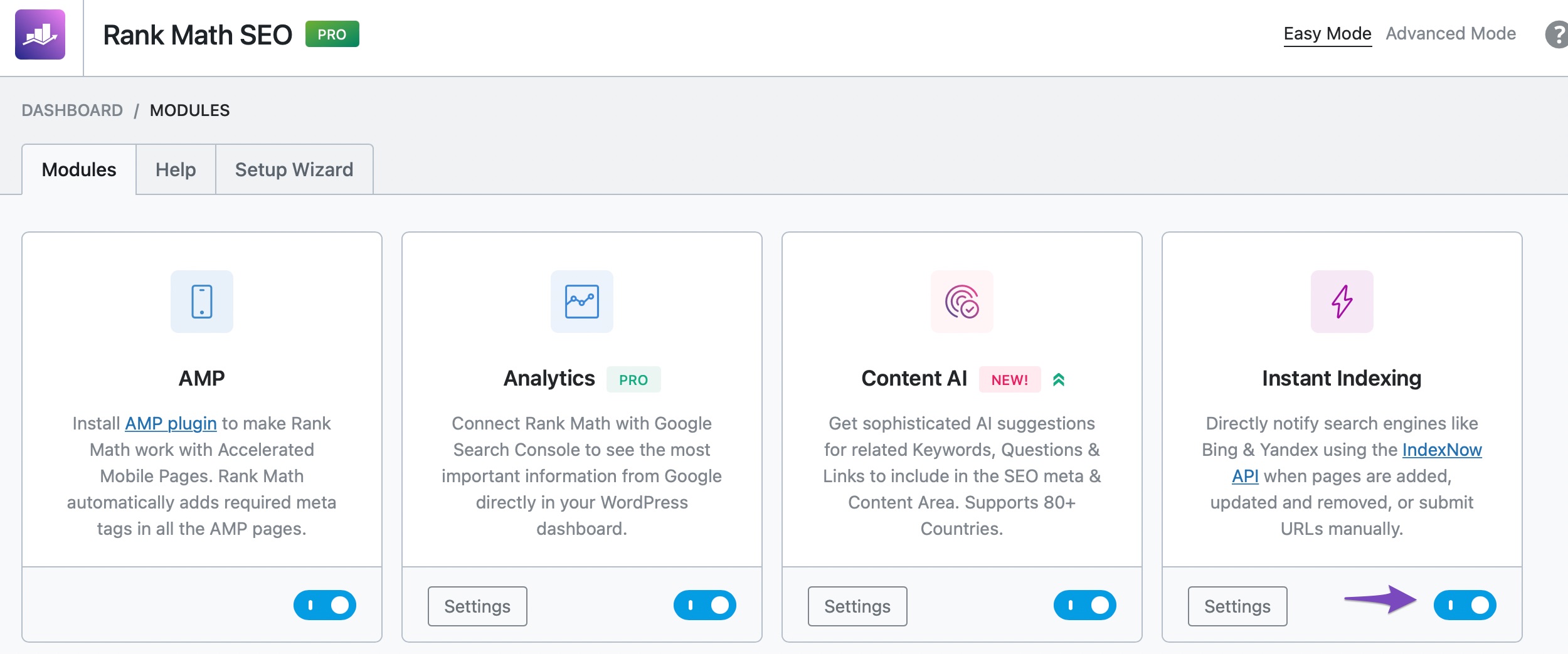
While passing the quality checks, search engines take a few days to index your pages. To inform search engines to index your pages instantly, use Rank Math’s Instant Indexing feature. To use this feature, enable the Instant Indexing module by navigating to WordPress Dashboard → Rank Math SEO.
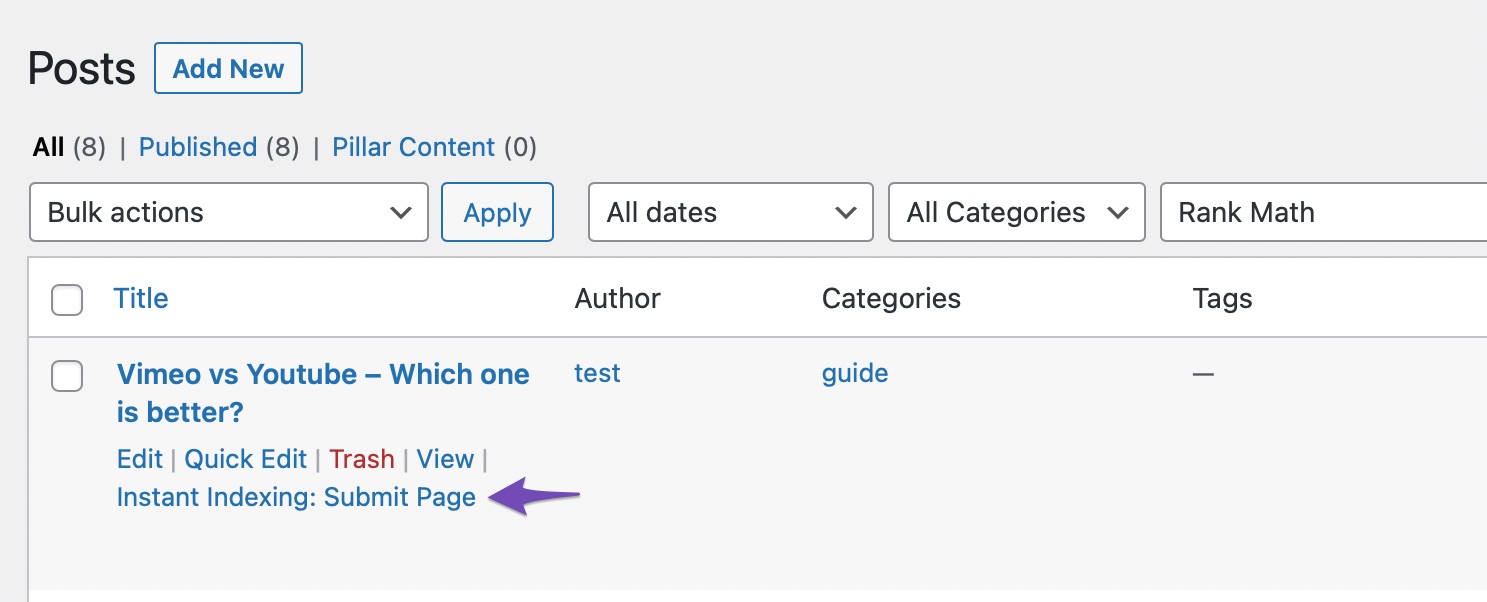
Next, on the Posts page, hover over the post you wish to index and select the Instant Indexing: Submit Page option, as shown below.
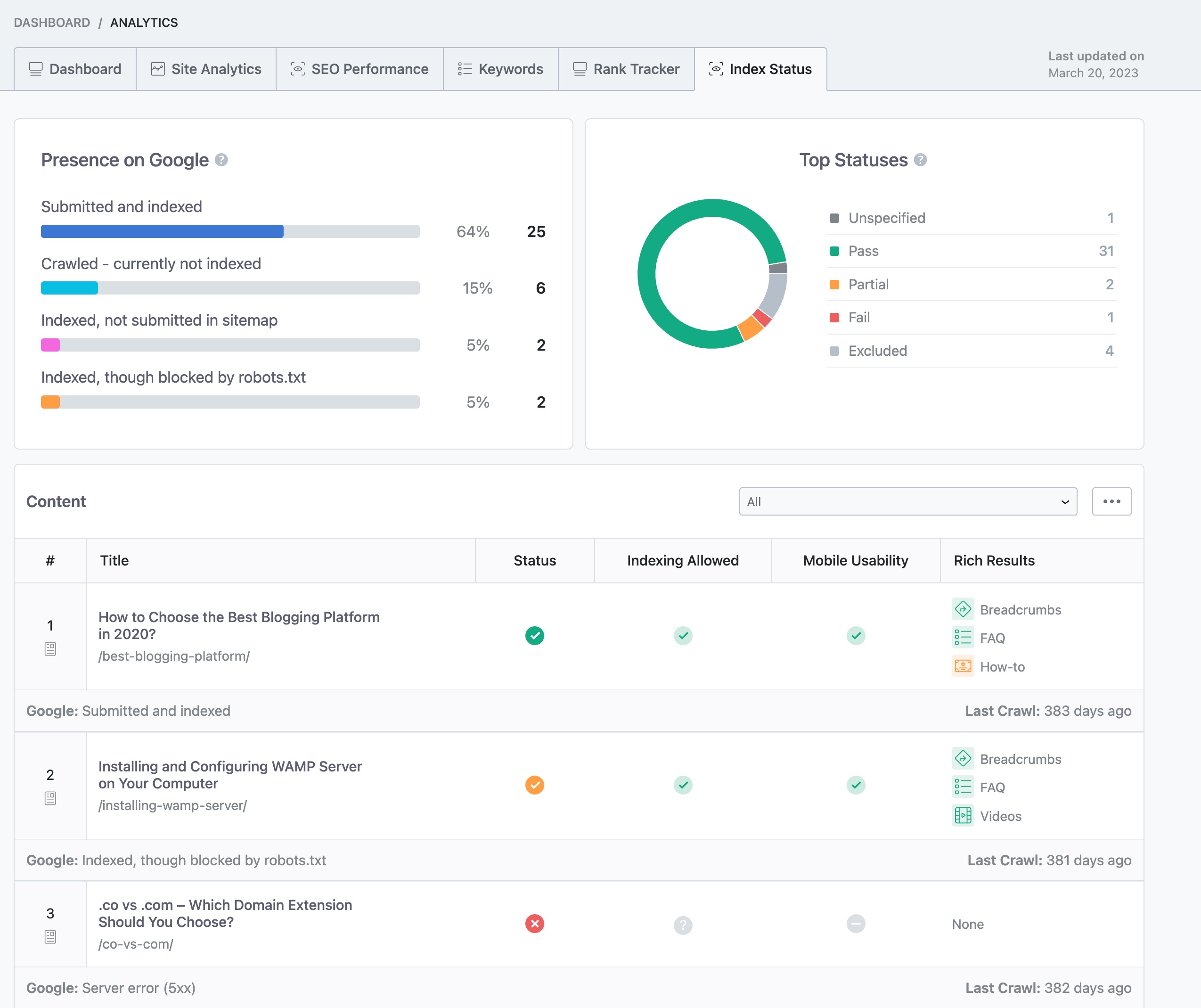
You can check your page’s index status within your WordPress dashboard by navigating to Rank Math SEO → Analytics → Index Status. However, if you’re a Rank Math PRO user, you can access advanced Index stats.
And that’s it! We hope the article helped you understand why your pages are excluded from the search index with this status. But if you still have absolutely any questions, please feel free to reach our support team directly from here, and we’re always here to help.