When controlling search engine interactions with your web pages, you have two main options: the robots meta tag and x-robots headers.
While they seem alike in guiding crawlers on indexing pages, understanding their key difference is essential.
In this knowledgebase article, we’ll explain what robots meta and x-robots tags are, how they function, and most importantly, the key difference between them.
So, let’s get started.
1 What Is the Robots Meta Tag?
The robots meta tag tells search engine crawlers which pages on your website should or should not be indexed and crawled.
It is placed in the <head> section of your HTML document and is written in the following format:
<meta name="robots" content="noindex">
2 When to Use a Robots Meta Tag
Here’s a list of some scenarios when you might want to use the robots meta tag:
- To prevent search engines from indexing duplicate content on your website.
- To prevent a snippet of a webpage from being displayed in search results if you do not want the snippet to be visible to users.
- Use the robots meta tag to prevent a webpage from being indexed if it is a private page, a test page, or a page still under construction.
- To prevent search engines from indexing pages irrelevant to search results (e.g., admin and thank-you pages).
- When you want to indicate whether search engines should follow the links on a webpage.
- Use the robots meta tag to prevent a webpage from being cached if it contains sensitive information or changes frequently.
3 The Attributes and Values of a robots meta tag
Robots meta tags are comprised of two attributes: name and content.
It is essential to provide values for both attributes. Let’s discuss what these values entail.
3.1 The Name Attribute
The name attribute specifies which crawlers should follow the instructions provided in the content attribute. This value is also referred to as a user-agent (UA), as crawlers need to be identified by their UA token when requesting a page.
For example, Google recognizes two user agent tokens:
- googlebot: for all text results.
- googlebot-news: for news results.
Google disregards any other value.
The UA value applies to all crawlers, and if needed, you can include multiple robot meta tags in the <head> section.
Let’s consider an example. If you wish to prevent your pages from appearing in Google or Bing searches, you can add the following meta tags respectively:
<meta name="googlebot" content="noindex">
<meta name="bingbot" content="noindex">
In this example, “googlebot/bingbot” is the name, and “noindex” is the content attribute.
3.2 The Content Attribute
The content attribute specifies the directives that search engine crawlers should follow when indexing or crawling a web page.
Google allows for using content attributes (values) that work in both robots meta tags and x-robots. This means you can also utilize these values in the x-robots tag.
Below is a list of them:
all
The all value is equivalent to index and follow values but have no effect if explicitly listed.
Example: <meta name="robots" content="all">
noindex
The noindex value prevents search engines from showing a page, media, or resource in search results.
Example: <meta name="robots" content="noindex">
nofollow
The nofollow value instructs search engine crawlers not to follow any links on a web page, preventing the passing of link equity to linked pages.
But note that they can still be indexable if backlinks point to them.
Example: <meta name="robots" content="nofollow">
none
This value instructs search engine crawlers not to index a page and not to follow any links on it. It’s equivalent to noindex and nofollow values.
Example: <meta name="robots" content="none">
noarchive
The noarchive value prevents search engines from showing a cached copy of a page on search results. Also, content from pages marked with the noarchive value will not be included or referenced in Microsoft Bing AI responses.
Example: <meta name="robots" content="noarchive">
Note: Google no longer supports the noarchive value because it no longer caches copies of pages for search results.
nosnippet
This value stops search engines from displaying a text snippet or video preview of a page in search results.
However, a static image thumbnail may still be visible if it has a better user experience.
Example: <meta name="robots" content="nosnippet">
max-snippet:[number]
The max-snippet:[number] value specifies the maximum text snippet length that search engines can show for a page in search results. The [number] represents the maximum number of characters allowed for the snippet.
To show how its be set up:
- If value = 0, they will not show a text snippet.
- If value = -1, there is no snippet length limit. A search engine will choose the length itself.
Example: <meta name="robots" content="max-snippet:150">
From this example, the maximum length of the displayed snippet is set to 150 characters.
Just note that a URL may appear and doesn’t affect video or image previews.
indexifembedded
The indexifembedded value instructs search engines to index the content of a web page only if it is embedded on another page through iframes or similar HTML tags., not if it is accessed directly.
Example: <meta name="robots" content="indexifembedded">
max-image-preview: [setting]
The max-image-preview: [setting] value controls the maximum image preview size that can be displayed in search results. The [setting] can be set to none, standard, or large.
Here is what they mean:
- none: No image preview will be shown.
- standard: A default that an image preview may be shown.
- large: A larger image preview may be shown up to the viewport’s width.
Example: <meta name="robots" content="max-image-preview:large">
This specifies a large-sized image preview in search results.
max-video-preview: [number]
The max-video-preview: [number] value specifies the maximum video preview duration in search results.
The special values are used:
- 0: A static image can be used based on the max-image-preview setting.
- -1: There is no limit.
Example: <meta name="robots" content="max-video-preview:480">
This sets the video preview size to 480 pixels.
notranslate
The notranslate value instructs translation services not to translate a web page’s content, helping to maintain the original language and context.
Example: <meta name="robots" content="notranslate">
noimageindex
This value instructs search engines not to index any images on a page.
Example: <meta name="robots" content="noimageindex">
unavailable_after: [date/time]
The unavailable_after: [date/time] value specifies a date and time after which search engines should no longer crawl or index a web page’s content.
The date/time should be in a commonly used format like RFC 822, RFC 850, or ISO 8601.
For example: <meta name="robots" content="unavailable_after:2022-12-31T23:59:59+00:00">
This value informs search engines to stop crawling or indexing the page after December 31, 2022, at 23:59:59 UTC.
If any of these rules are unspecified, Google will default to displaying information found on any page in search results.
You can also form a multi-rule directive by combining robots meta tag rules with commas or using multiple meta tags.
For example, this meta tag prevents web crawlers from indexing the page and crawling its links:
1. A comma-separated list- <meta name="robots" content="noindex, nofollow">
2. For multi-meta tags –
<meta name="robots" content="noindex">
<meta name="robots" content="nofollow">
Note: The “name” and “content” attributes are case-insensitive, meaning uppercase and lowercase letters can be used interchangeably without affecting functionality.
4 Indexing Directives Comparison Across Search Engines
Now, let’s compare the support for various indexing directives across different search engines.
The table below lists the indexing directives and the search engines that support them:
| Value | Bing | Baidu | Yandex | |
| all | ✅ | ❌ | ✅ | ❌ |
| noindex | ✅ | ✅ | ✅ | ✅ |
| nofollow | ✅ | ✅ | ✅ | ✅ |
| none | ✅ | ❌ | ✅ | ❌ |
| noarchive | ❌ | ✅ | ✅ | ✅ |
| nosnippet | ✅ | ✅ | ❌ | ❌ |
| max-snippet:[number] | ✅ | ✅ | ❌ | ❌ |
| indexifembedded | ✅ | ❌ | ❌ | ❌ |
| max-image-preview: [setting] | ✅ | ✅ | ❌ | ❌ |
| max-video-preview: [number] | ✅ | ✅ | ❌ | ❌ |
| notranslate | ✅ | ❌ | ❌ | ❌ |
| noimageindex | ✅ | ❌ | ❌ | ❌ |
| unavailable_after | ✅ | ❌ | ❌ | ❌ |
| noyaca | ❌ | ❌ | ❌ | ✅ |
5 How to Implement robots meta tag in WordPress
To add the robots meta tag to your WordPress site, use the Rank Math SEO plugin. After installing and activating the plugin, configure the settings to access the Robots Meta option for each post or page.
Then, navigate to the Advanced tab in Rank Math’s Meta Box within the page/post editor to set up both basic and advanced robots meta options.
Any changes you make will impact how search engines index your site.
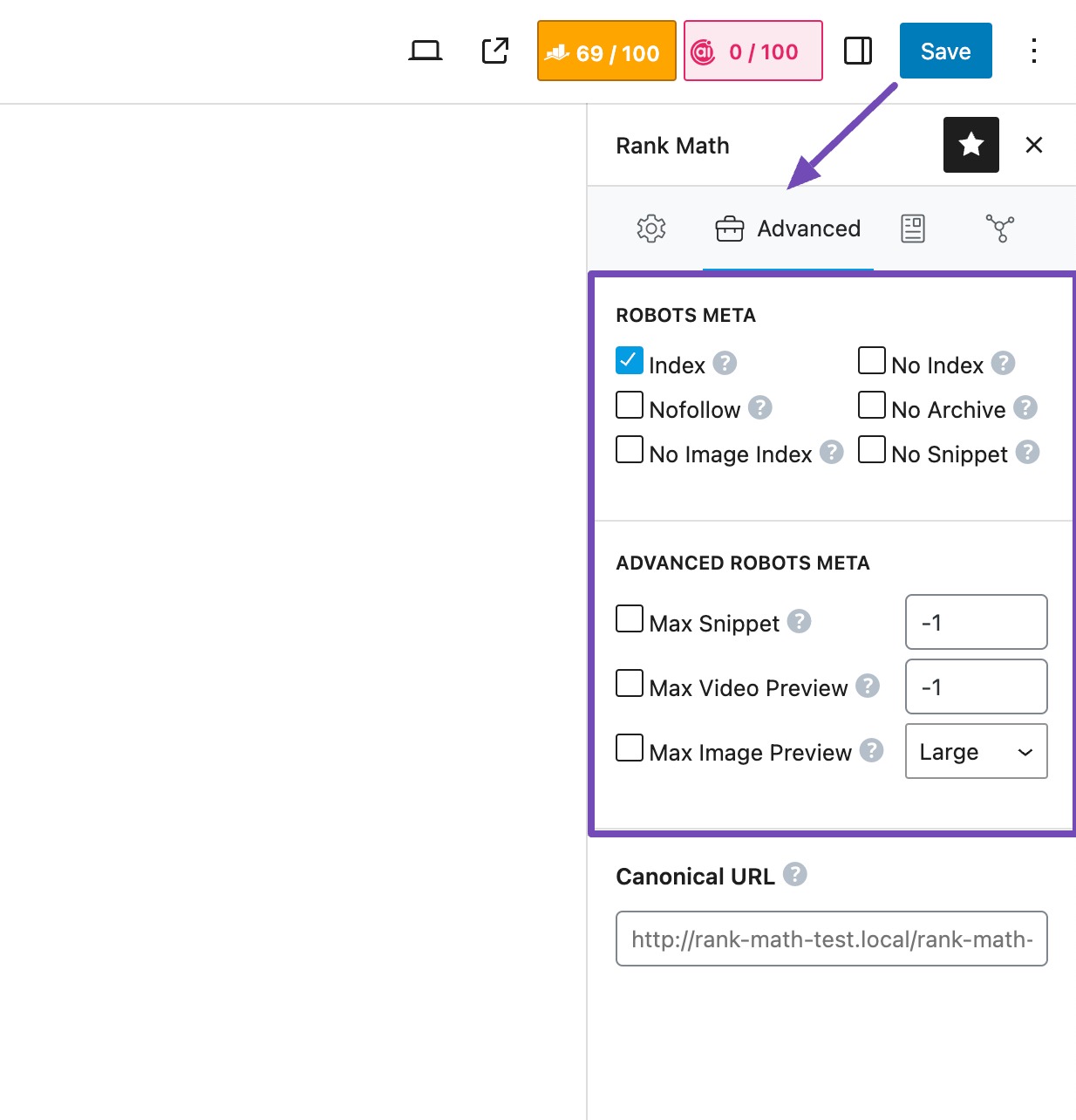
You can find more information here for further details on how it operates.
In the previous section, we demonstrated an example of using the indexing values on robots meta tags only. These same values can also be used on x-robots using their structuring style. We will discuss x-robots tags in the next section.
6 What is an X-Robots Tag?
The X-Robots Tag is an HTTP header directive that provides search engines extra instructions for handling a specific page or resource.
It can dictate whether a page should be indexed, if crawlers should follow it, and if it should appear in search results.
X-Robot tags can also set a crawl delay, limit the page depth, and prevent pages from being cached.
Here’s an example format: X-Robots-Tag: noindex.
This format tells crawlers not to index the page.
This format also applies to other indexing values discussed above, such as nofollow, all, noarchive, nosnippet, none, etc.
The X-Robots-Tag can optionally include a user agent before the rules. For instance, the following X-Robots-Tag HTTP headers selectively allow a page to be displayed in search results for Google and Bing:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: bingbot: noindex, nofollow
7 When to Use the X-Robots Tag
While the x-robots tag usage is similar to the meta robots tag, it offers some key advantages. Here are the top situations where using the x-robots tag is recommended:
7.1 Targeting Non-HTML Files
The meta robots tag only impacts HTML pages. If you want to control crawling and indexing for non-HTML content like PDFs, images, videos, or Javascript files, you need the x-robots tag.
7.2 Site-Wide Directives
The x-robots tag allows you to set directives applicable to entire sections of your website or specific file types in one place, offering greater efficiency.
7.3 User Agent Targeting
With x-robots tag, you can direct specific search engine crawlers (user agents) according to your preference, providing different indexing behaviors for different bots, similar to the robots meta tag.
7.4 Dynamic Content & Parameters
For content generated dynamically or URLs with parameters, x-robots tag is more effective than meta robots as it’s applied at the response level, offering more precise control.
8 How to Add X-Robots Tag in WordPress
The configuration varies based on the web server type and the pages/files you want to exclude from the index.
Also, proceed with this implementation only if experienced, as a small syntax error can lead to website malfunctions. You should also keep your backups ready in case of any issues.
For Apache servers, a common approach is to modify your website’s httpd.conf file or .htaccess files. An example of code for this purpose is
Header set X-Robots-Tag "noindex, nofollow"
And for the Nginx server, it should look like this
add_header X-Robots-Tag "noindex, follow";
9 Difference Between robots meta tag and X-Robots Tag
While both robots meta tags and x-robots tags aim to control how search engines crawl and index your website, they differ in several key aspects:
- The Robots Meta Tag is embedded in the HTML code of a specific page, while the X-Robots Tag is included in the HTTP response header for a URL, applicable to all content served at that URL.
- The Robots Meta Tag only affects the page containing the tag and its content. On the other hand, the X-Robots Tag can be applied to any file type (HTML, PDF, images, etc.) within the URL it governs.
- The Robots Meta Tag is limited to one page at a time and requires individual settings for each page, while the X-Robots Tag can be applied globally to affect entire sections of your website or file types based on patterns.
- The Robots Meta Tag is easier to implement, requiring no additional configuration. On the other hand, the X-Robots Tag requires server-side configuration or specific plugin features, potentially involving coding knowledge.
That’s It. We have successfully explored robots meta tag and x-robots, including how to implement them and their distinctions. If you have any further questions, please don’t hesitate to reach out to our support team here, they will be glad to help you.