The robots.txt file informs search engines which pages on your website should be crawled. This can easily be edited with the Rank Math SEO plugin. If you aren’t already using Rank Math on your website – learn more & get started here.
In this tutorial, we’ll show you how you can edit your robots.txt file with the help of Rank Math.
Table of Contents
1 Why is Robots.txt Important?
Before getting started with editing the robots.txt file, let’s try to understand its importance.
When search engine crawlers or any bots land on your website, they would first look for the presence of the robots.txt file, as it would contain important instructions on how search engines should crawl your website.
Although most bots would honor your request, some malware bots, and email scraping bots aren’t likely to follow the instructions from robots.txt. But that said, these bad bots, in most cases, have barely any traffic volume, to begin with, and hence it is safe to ignore such bots.
2 How to Find Your robots.txt File
Your robots.txt file is located in the root of your domain. You can view it by typing your domain name and /robots.txt into your browser’s address bar. For example, https://yourdomain.com/robots.txt. Once done, your robots.txt file will be displayed, as shown below.

The URL will display the content of your physical or virtual robots.txt file. If you’re using Rank Math, you can edit the contents of the virtual robots.txt file as shown below.
3 How to Edit Your Robots.txt With Rank Math

Rank Math makes it possible to edit your robots.txt file right inside your WordPress dashboard by creating a virtual file. If you prefer to edit your robots.txt file using Rank Math, you’ll need to delete the actual robots.txt file (if any) from your website’s root folder using an FTP client.
Now that said, to edit your robots.txt file with Rank Math, you can follow the steps below.
3.1 Navigate to Edit Robots.txt
To begin with, head to WordPress Dashboard → Rank Math SEO.
Next, navigate to the top-right corner of the page and ensure that Advanced Mode is enabled. Once done, click General Settings, as shown below.
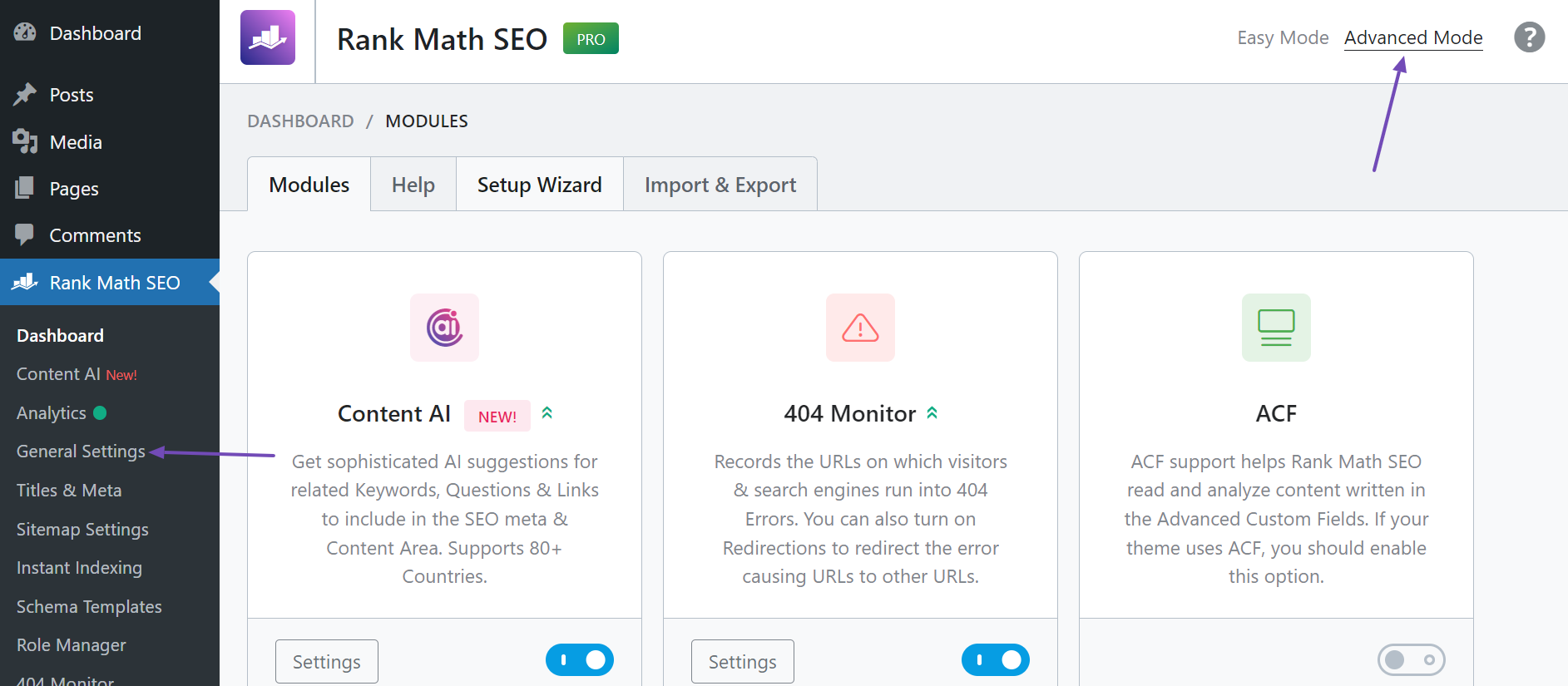
Then, click Edit robots.txt.
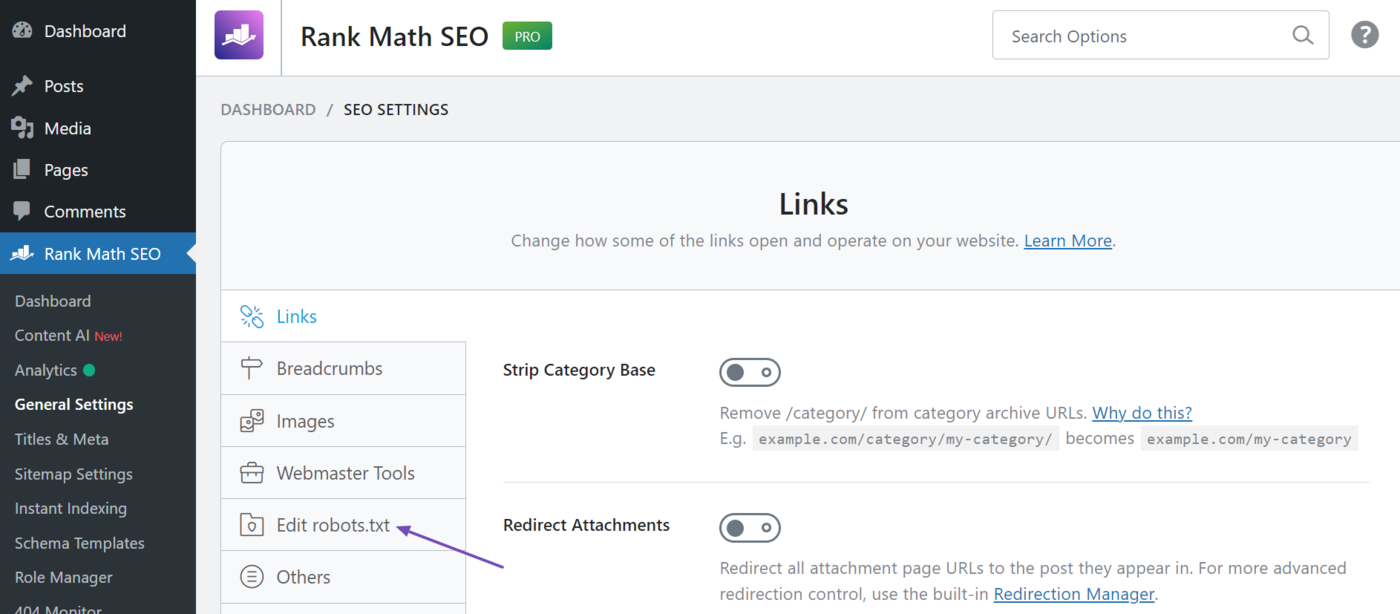
You will be presented with your robots.txt editor. If you are using the free version of Rank Math, you will see the default robots.txt file, which appears as shown below.
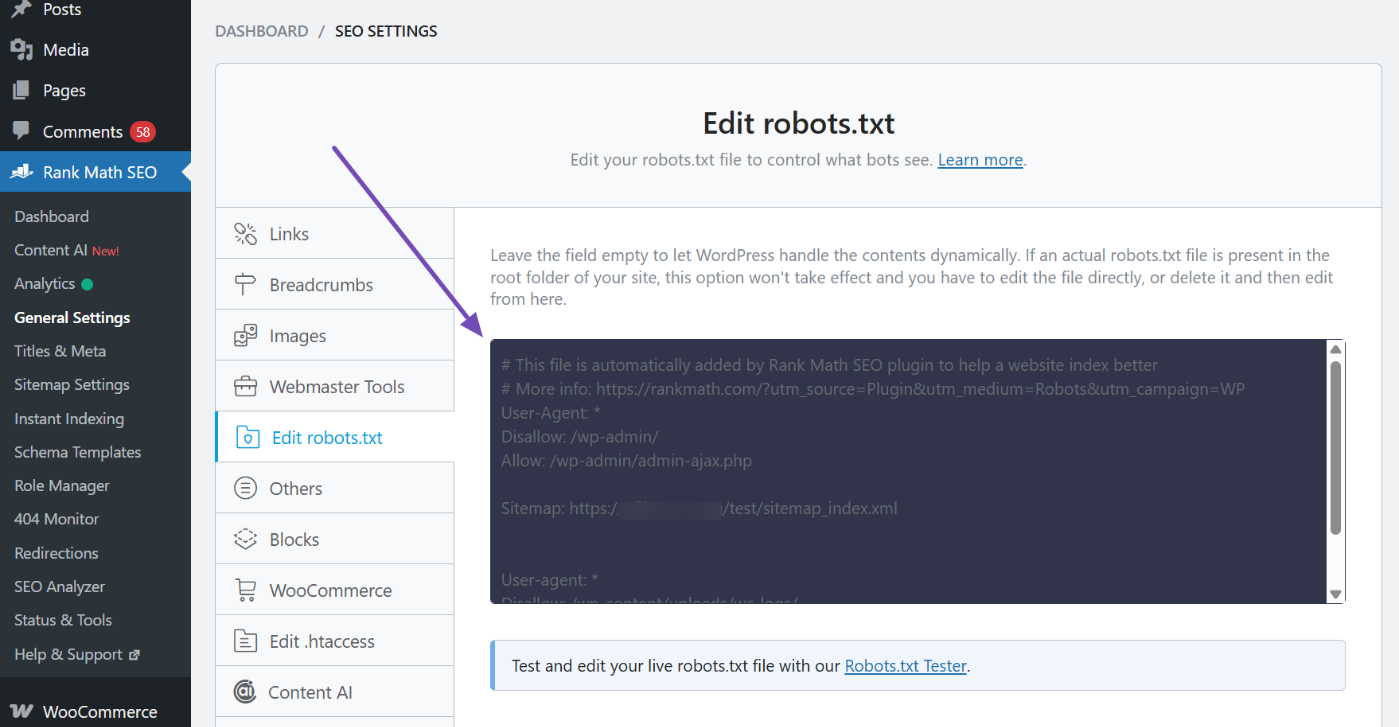
However, if you are a Rank Math PRO user, the robots.txt file will come with a more advanced editor and tester, as shown below.
3.2 Add Code in Your Robots.txt
By default, Rank Math would automatically add a set of rules (including your Sitemap) to your robots.txt file. However, you can always add or edit the code as you prefer in the available text area.
If you’re unsure about the rules available to use with your robots.txt file, hold on, as we will also discuss them shortly in this article. And if you ever need a copy of the default robots.txt rules, you can refer to them here.
If you’re a free Rank Math user, you can edit your robots.txt file directly, as shown below. Then, use the Robots.txt Tester link beneath it to verify your changes in our external tool.
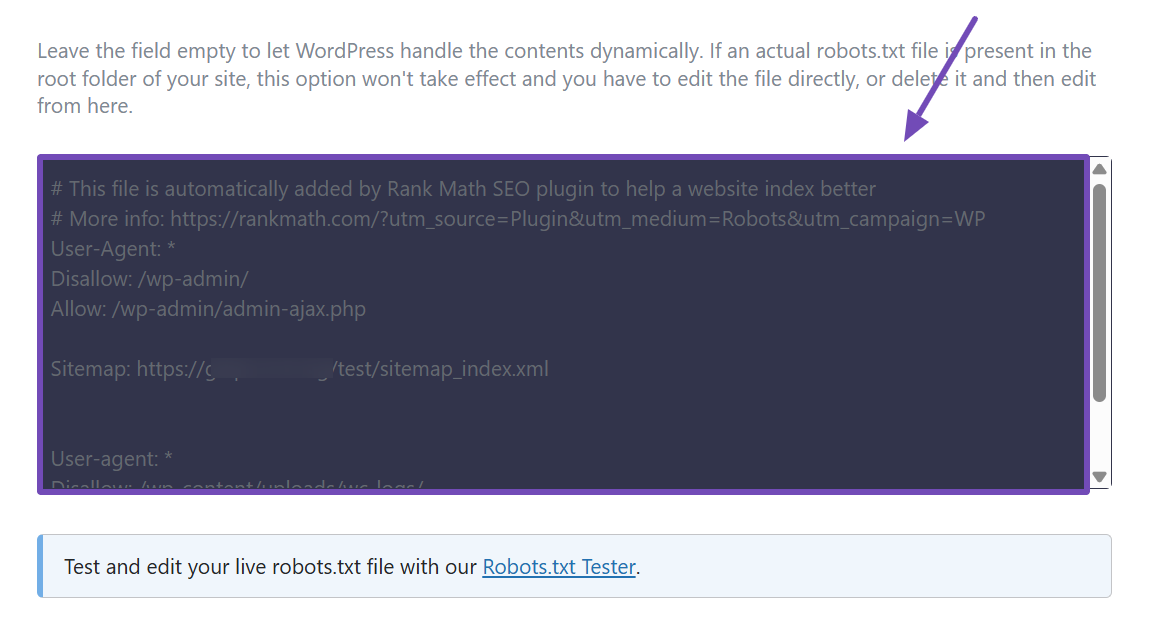
However, if you’re a Rank Math PRO user, you can edit your robots.txt file and test your changes simultaneously.
To do this, select the EDITOR option, make your configurations, and if you’re happy with them, click the Validate Code button to test the robots.txt file directly on your site. If not, you can click the Revert Changes button to redo your configurations.
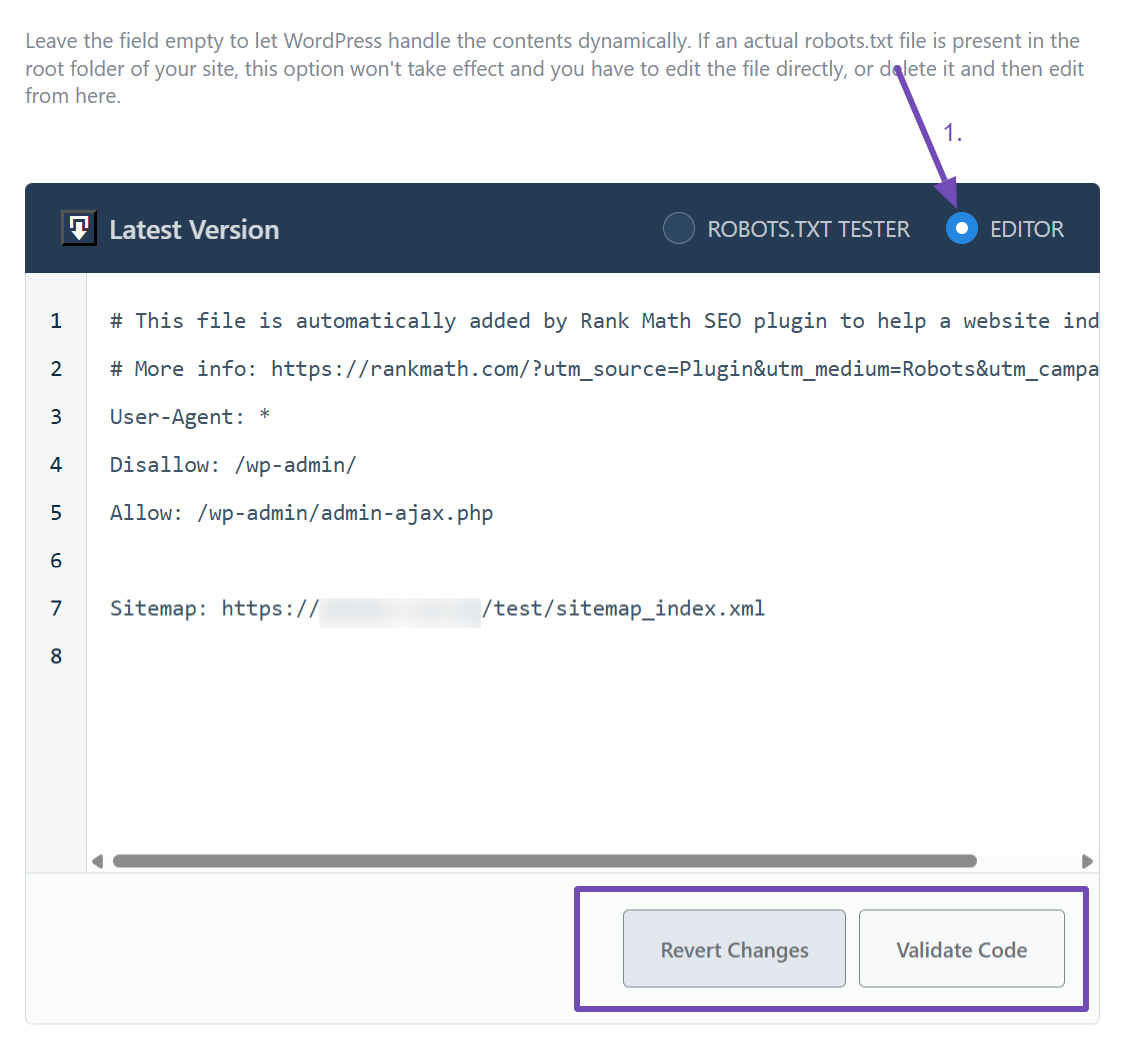
When you click the Validate Code button, you’ll be taken to the tester. Scroll down a bit, and you’ll see that your site is already added. From there, you can select the User Agent you want to test for, then click the Test button to run the check, as shown below.
Please note: The robots.txt tester can only be used on the specific website where Rank Math is installed.
3.3 Save Your Changes
Save your modifications by clicking Save Changes after making the necessary modifications to the file.
Caution: Please exercise caution when making any major or minor changes to your website via robots.txt. While these changes can improve your search traffic, they can also do more harm than good if you are not careful.
4 Robots.txt Syntax
Now that we’re aware of how to edit the robots.txt with Rank Math, let us dive into the rules that you can add to your robots.txt file.
A rule (or a directive) in robots.txt is simply an instruction to the crawler on which pages to index. It is a simple way of telling, ‘Hey crawler, you should be crawling these pages, but not the pages from those directives, ‘ and so on.
When it comes to adding rules to your robots.txt file, there are some general guidelines you should be following:
- A robots.txt file can have one or more groups, and each group consists of multiple rules.
- Each group begins with a User-agent and then specifies which directories or files the agent can access and cannot access.
- By default, it is assumed that a user-agent can crawl any page on your website unless you specifically block access using the disallow rule.
- Rules are case-sensitive.
#character marks the beginning of the comment.
And now, let’s look into the different rules (or directives) that can be used in robots.txt:
| User-agent | The rule indicates the web crawler (or the bot) the group is targeting. The complete lists of Google user agents and Bing user agents are available here. |
| Disallow | The rule refers to the directory or page on your website that you don’t want the user agent to crawl. |
| Allow | The rule refers to the directory or page on your website that you want the user agent to crawl. |
| Sitemap | The rule indicates the sitemap of the website and should be entered as a fully qualified URL. Though it is optional, it is a good practice to have one. |
Please note that any line in your robots.txt that does not match the above directives is completely ignored. And all directives except sitemap will accept the wildcard * as a prefix, suffix, or the entire string. $ is another wildcard that is honoured by both Google & Bing, and it indicates the end of the URL.
5 Robots.txt Rule Examples
Although there are only a handful of rules allowed in robots.txt, it is still easy to make mistakes. Hence, we have some examples of robots.txt rules that you can use right away. However, note that the specific rule you use may differ depending on your URL structure.
5.1 Disallow Crawling of the Entire Website
This disallow rule will prevent all the bots from crawling your entire website. The / here represents the root of the website directory and all the pages that branch out from it. Thus, it includes the homepage of your website and all the pages linked from it.
We don’t recommend using this rule on a live website, as search engine crawlers will not crawl and index your website. However, that being said, this rule is primarily used on development and staging sites, where you wouldn’t want crawlers to access and index the site’s content.
User-agent: *
Disallow: /5.2 Disallow Crawling of the Entire Website for a Specific Bot
Instead of blocking access to all the web crawlers, if you wish to secure your website access from specific crawlers, replace the wildcard in the User-agent with the name of the crawlers. For example, the following rule will block access to the Adsbot of Google.
User-agent: AdsBot-Google
Disallow: /And, if you want to mention explicitly that other bots can crawl your website, then use the following group of rules.
User-agent: AdsBot-Google
Disallow: /
User-agent: *
Allow: /5.3 Rank Math Default Robots.txt Rules
Rank Math, by default, includes the following rules in the robots.txt file. If you ever happen to remove these rules from your robots.txt but later want to include them, you can copy-paste the following rules. Make sure to replace yoursite.com with your domain name.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://yoursite.com/sitemap_index.xml5.4 Disallow Access to Specific Directory
Let’s assume you have a directory on your page that you don’t want to appear in search results pages. For example, many WordPress sites have their login pages at yourdomain.com/wp-admin.
Bloggers do not want such login pages to appear in search results because they are unhelpful and may pose a security risk. So, they create robots.txt files to block search engines from crawling the /wp-admin/directory.
User-agent: *
Disallow: /wp-admin/5.5 Disallow Crawling of Files of a Specific File Type
Your site may host certain files you do not want search engines to index and display on their search result pages. For example, you may offer PDF files that you do not wish to appear on search result pages. In that case, you will include the rule below in your robots.txt file.
Note: Blocking CSS and JavaScript files is not recommended by Google, as it can prevent the page from rendering and potentially affect your search traffic.
User-agent: *
Disallow: /*.pdf$5.6 Disallow AI Models & Chatbots Using Your Content
If you do not want Google to use your website’s content to train its Gemini and Vertex AI models, you can disallow its user-agent.
Please note that this will not prevent Google from crawling and indexing your website’s content for search results. Plus, it won’t prevent your content from appearing in Google’s AI Overviews in search results.
User-agent: Google-Extended
Disallow: /Similarly, if you want to prevent your content from being used to train an AI model, you can disallow the corresponding user agent. For instance, you can block OpenAI from using your content to train its AI models (including ChatGPT) using the rule below.
User-agent: GPTBot
Disallow: /Note: This rule will also block ChatGPT users from using the ChatGPT-User bot to browse your site.
5.7 Disallow Crawling of Internal Search Result Pages
When visitors perform a search on a site using the search bar, the site returns the results on a search results page. This page has a URL that search engines may index.
For example, when we search for “best yoga poses” on a site, it returns a results page. That page may have a URL like https://yourdomain.com/?s=best+yoga+poses.
Search engines can index such pages. However, these pages are usually unhelpful, of low quality, and consume the site’s crawl budget. So, use the rule below to block search engines from indexing such pages.
User-agent: *
Disallow: /?s=5.8 Disallow Crawling of Category Pages
You may want to block search engines from crawling specific category pages on your site. This could be because the page is a duplicate, does not contain sufficient content, or is of low quality.
For example, you may not want search engines to crawl the category page at yourdomain.com/poses because it contains too little content. However, you want search engines to crawl the blog posts in the category. For example, yourdomain.com/poses/best-yoga-poses. In this case, you use the rule below.
User-agent: * Disallow: /poses$
5.9 Disallow Crawling of Faceted Result Pages
Ecommerce sites typically provide their visitors with faceted navigation. This allows their visitors to easily filter and refine product searches based on attributes like price, size, and color.
For example, a visitor who wants a large gray shirt will select the options from the faceted navigation menu, and the site will return with a results page containing large gray shirts. The URL of that page will typically look something like this: yourdomain.com/tshirts?color=gray&size=large.
Such URLs can cause duplicate pages and low-quality content issues, so most stores add their faceted navigation keys to their robots.txt file. If color and size are the only keys on your site, you will use the robots.txt rule below:
User-agent: *
Disallow: *size=*
Disallow: *color=*
Conclusion — Edit Your Robots.txt File & Validate
And, that’s it! We hope the tutorial helped you edit your robots.txt file using Rank Math. But please note, you can also manually create & edit your robots.txt file, and if you prefer that way, you can simply upload the file to the root folder of your website (on your server) and edit it — if you’re unsure of where to upload the file, you can always check with your web host for further assistance.
Once you’ve edited the robots.txt file, you can always try to simulate the crawling of pages on your website with Google bots and check if they can access the page or not using a robots.txt tester.
If you still have any questions about editing your robots.txt file with Rank Math or facing issues while editing, you’re always more than welcome to contact our dedicated support team, and we’re available 24/7, 365 days a year…