Not all web crawlers are the same. While search engine crawlers like Googlebot improve your visibility, others, such as scrapers and spam bots, can slow down your site, steal your content, or pose security risks.
If you’re seeing suspicious traffic or unwanted activity, chances are a bad bot is behind it.
The good news? You can stop them.
In this Knowledgebase article, we’ll walk you through the safest and most effective ways to block unwanted web crawlers from your site.
1 What Are Web Crawlers?
Web crawlers (also called bots, spiders, or robots) are automated programs that browse the internet and collect information from websites.
They move from one page to another by following links and indexing content as they go. This helps the systems behind them, like search engines, AI tools, or SEO platforms, understand what your site is about.
Some crawlers are useful. Others aren’t. And some ignore the rules entirely. Here are the main types:
- Search Engine Crawlers: These are the good bots, such as Googlebot and Bingbot, that help index your website so it shows up in search results.
- AI Web Crawlers: These are bots used by AI tools such as ChatGPT (GPTBot), Perplexity (PerplexityBot), or Anthropic (ClaudeBot) to crawl your site and learn from your content. Some follow your rules, others don’t.
- SEO and Monitoring Bots: Tools like Ahrefs, Semrush, or UptimeRobot send crawlers to analyze SEO performance, backlinks, and uptime.
- Scrapers and Data Harvesters: These are typically unwanted bots that steal your content, product data, or pricing information—often for shady or unauthorized purposes.
- Spam Bots: These crawl your site looking for forms or comment sections to flood with spam or malicious links.
- Hacking and Vulnerability Scanners: These bots are designed to probe your site for weak spots such as outdated plugins, exposed files, or admin areas. They’re the most dangerous type of crawler.
2 How Web Crawlers Work
Web crawlers work by sending automated requests to your website, just like a real visitor would. But instead of just viewing a page, they scan your content, follow links, and collect data for indexing or analysis.
They typically start from your homepage or sitemap, read everything on the page (text, links, metadata, etc.), then follow internal links to explore more of your site. The content they collect gets stored in large databases either for indexing in search engines or for training AI models.
Most well-behaved crawlers check your robots.txt file before crawling, to respect any rules you’ve set. But bad or malicious bots often ignore these rules entirely.
3 How to Identify Unwanted Web Crawlers on Your Site
Sometimes, you need to know the name of the crawler visiting your site before you can block it. But how do you find that out?
There are different ways to do this, but let’s go with the most straightforward one—checking your server logs. Your server logs store every single request made to your site, including bot activity. That’s where you’ll find the exact user-agent (bot name) trying to crawl your website.
To access this, log in to your hosting control panel and navigate to Site Summary/Statistics/Logs.
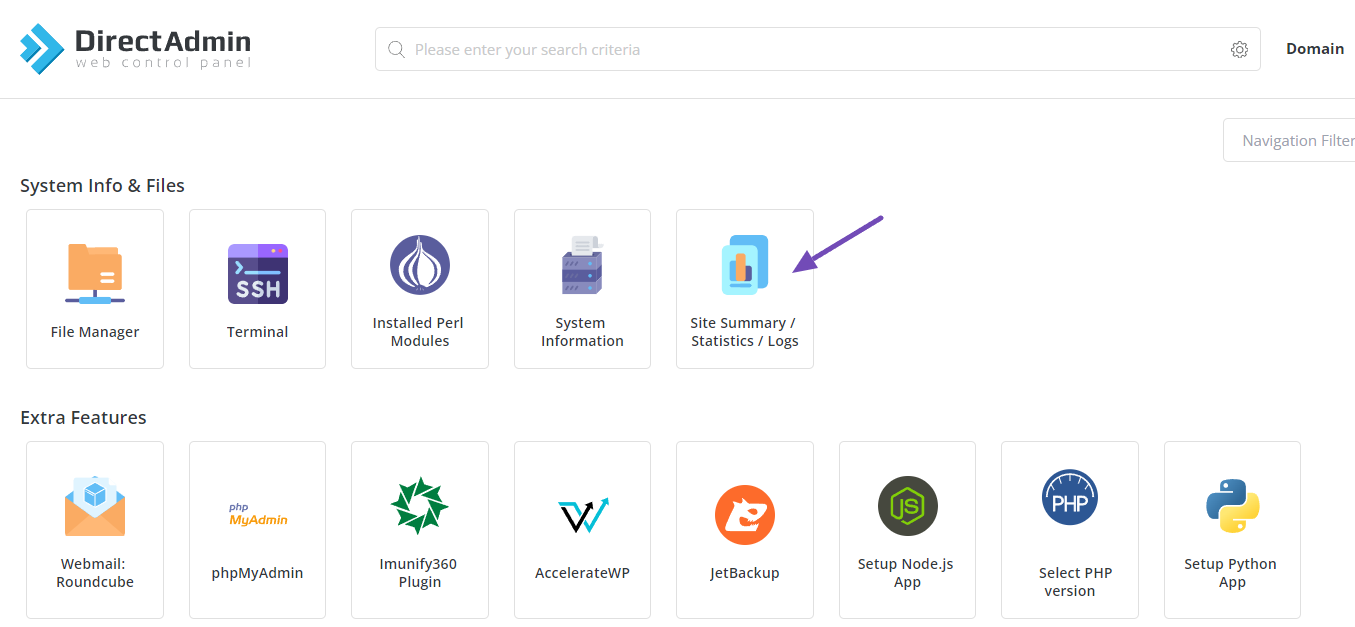
Once you’re in, look for the domain you want to inspect and open the Usage Log, as shown below.
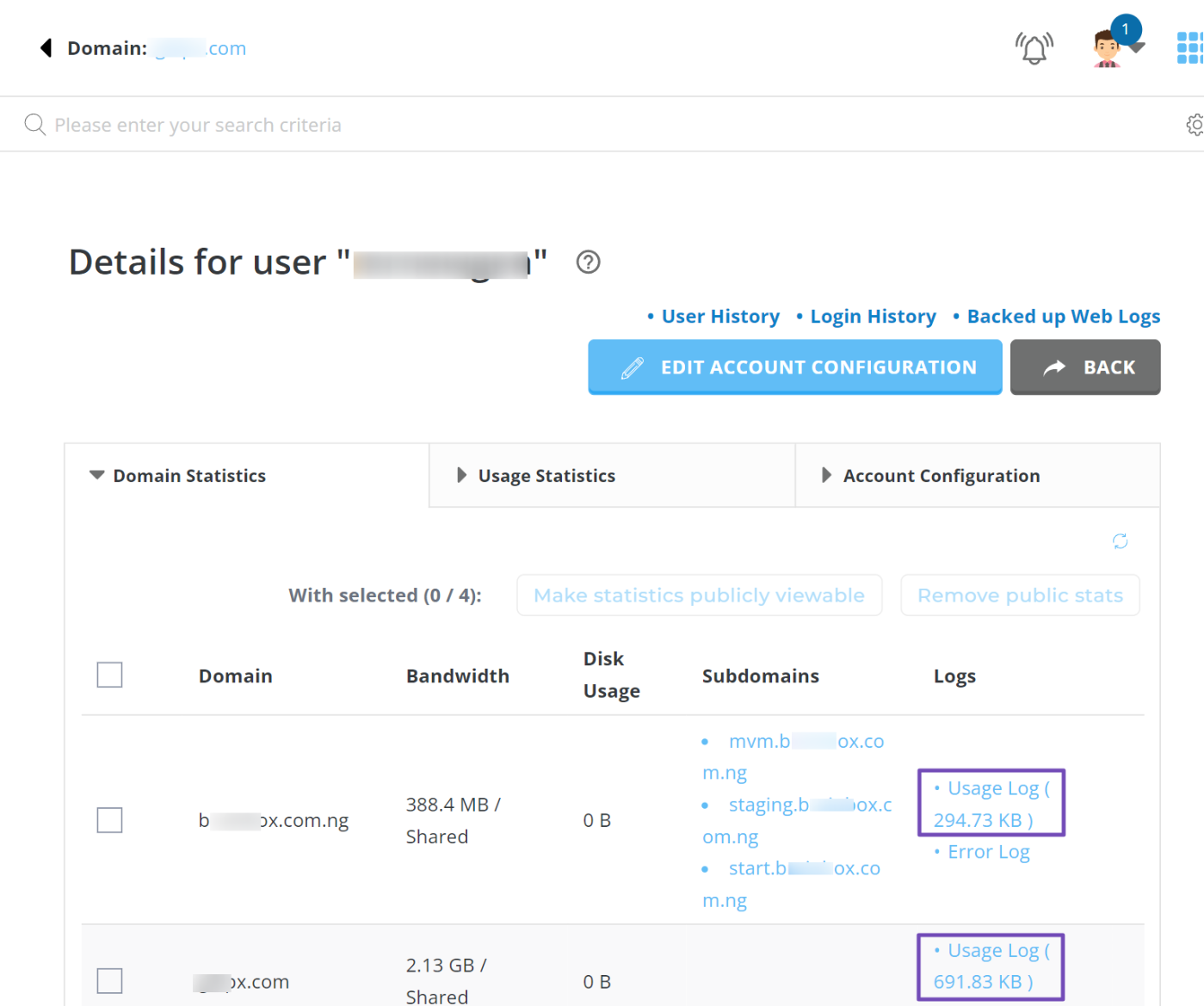
When the log loads, use Ctrl + F on your keyboard and type in ‘bot’ or ‘spider’ or even the name of any platform you suspect might be crawling your site. If the bot is present, the system will highlight it immediately.
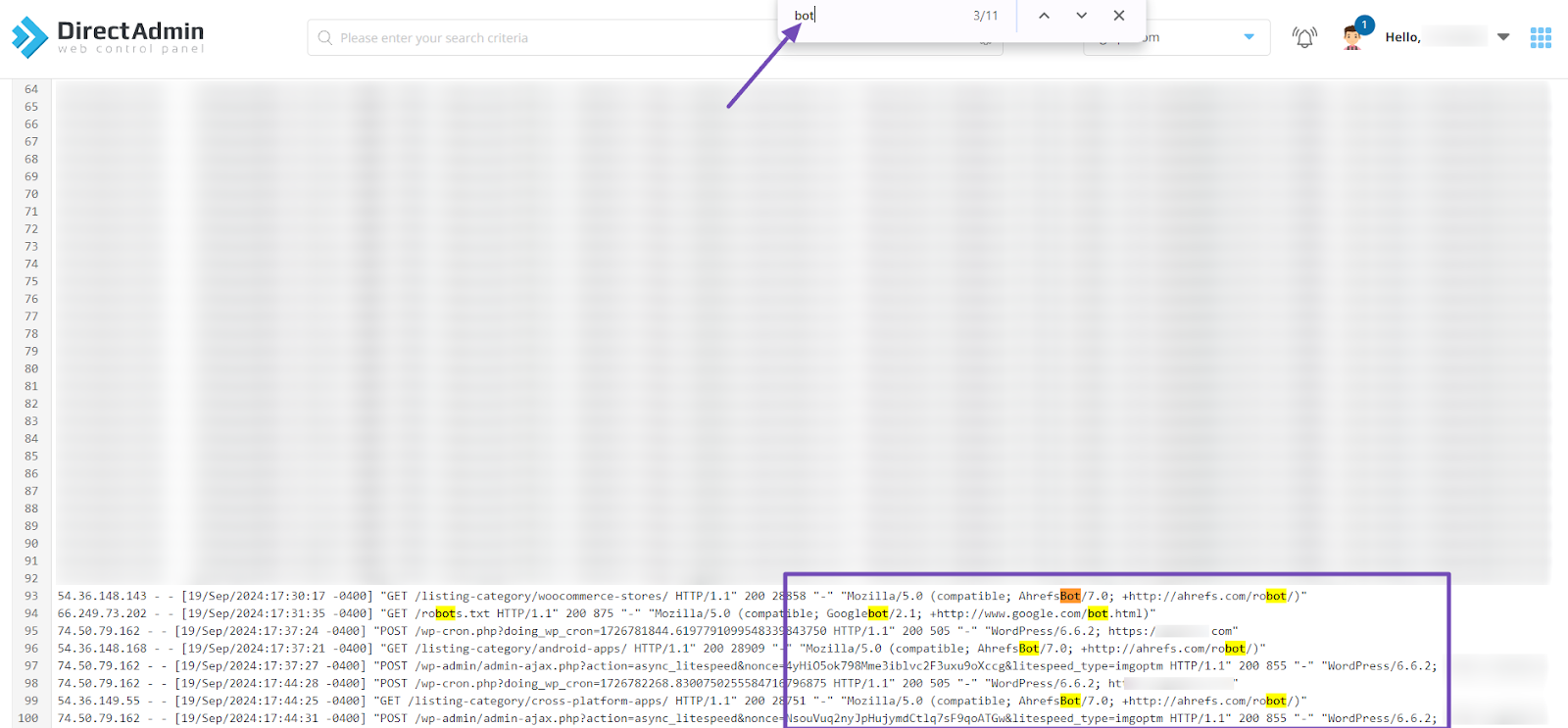
That way, you can spot the exact user-agent crawling your site and jot it down. Once you’ve got it, you’ll be ready to block it if it’s one of those unwanted bots you don’t want crawling your content again.
4 How to Block Unwanted Web Crawlers
Now that you know the type of bots you should block and you’ve probably taken note of their names, it’s time to actually block them.
But just a quick reminder: not all bots are bad. Be cautious not to block useful crawlers, such as Googlebot, Bingbot, OAI-SearchBot, and others, which help your site get discovered.
Let’s go over the best methods to block unwanted bots from crawling your site:
4.1 Block Using robots.txt
The robots.txt file is a standard way to tell crawlers which parts of your site they can or cannot access. But here’s the catch: only well-behaved bots follow these rules. Malicious or aggressive bots usually ignore them altogether.
That means this method is best suited for legitimate crawlers, such as search engines, SEO tools, and platforms that respect your robots.txt instructions.
So, how do you access and edit this file?
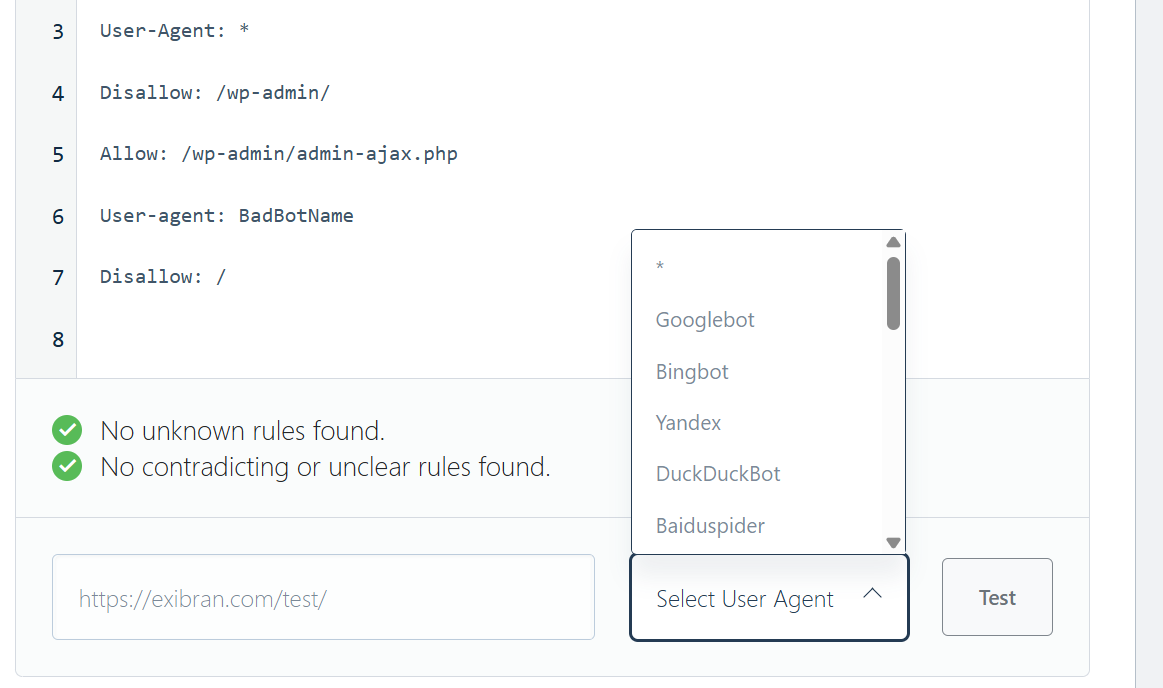
If you’re using WordPress, the easiest way is with Rank Math, the #1 SEO plugin. Once installed and set up: Go to Rank Math SEO → General Settings → Edit robots.txt.
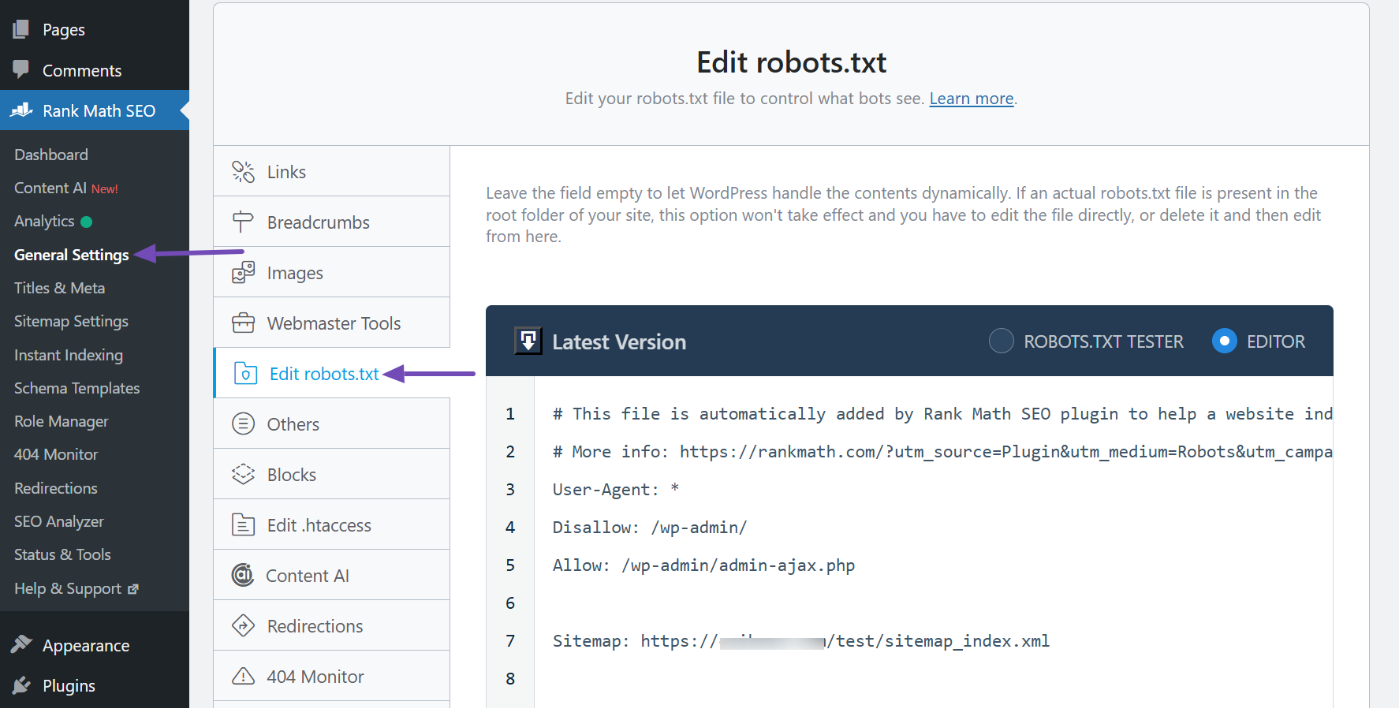
There, you can add something like this:
User-agent: BadBotName
Disallow: /Replace BadBotName with the actual user-agent name of the bot you want to block, e.g., GPTBot or any other crawler you’ve identified.
If you’re blocking multiple bots, just repeat the block for each one using the same format. Don’t forget to save your changes when you’re done.
In case you don’t want to block anything permanently, you can also preview and test your robots.txt directly using Rank Math PRO or with our external free robots.txt tester tool.
And if you need help editing this file properly, we’ve got a complete guide on how to manage your robots.txt using Rank Math.
4.2 Block Using .htaccess (For Apache Servers Only)
If your site is running on an Apache server, you can block unwanted crawlers using your .htaccess file.
This method is more potent than robots.txt because it blocks bots at the server level, before they use your resources.
Instead of editing .htaccess manually, you can conveniently do it right from your WordPress dashboard using Rank Math. If Rank Math is already installed, go to: Rank Math SEO → General Settings → Edit .htaccess.
From there, you can add either of the methods below.
Block Bots by User-Agent
If you’ve identified the crawler’s name (the user-agent), you can block it using this snippet:
# Block Unwanted Bots by User-Agent
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} ^.*(BadBotName|AnotherBot).* [NC]
RewriteRule .* - [F,L]
</IfModule>Replace BadBotName and AnotherBot with the actual user-agent strings you know or have found in your server logs.
Make sure to place this code above the # BEGIN WordPress line in your .htaccess file, as shown below. That way, it won’t be affected by WordPress updates.
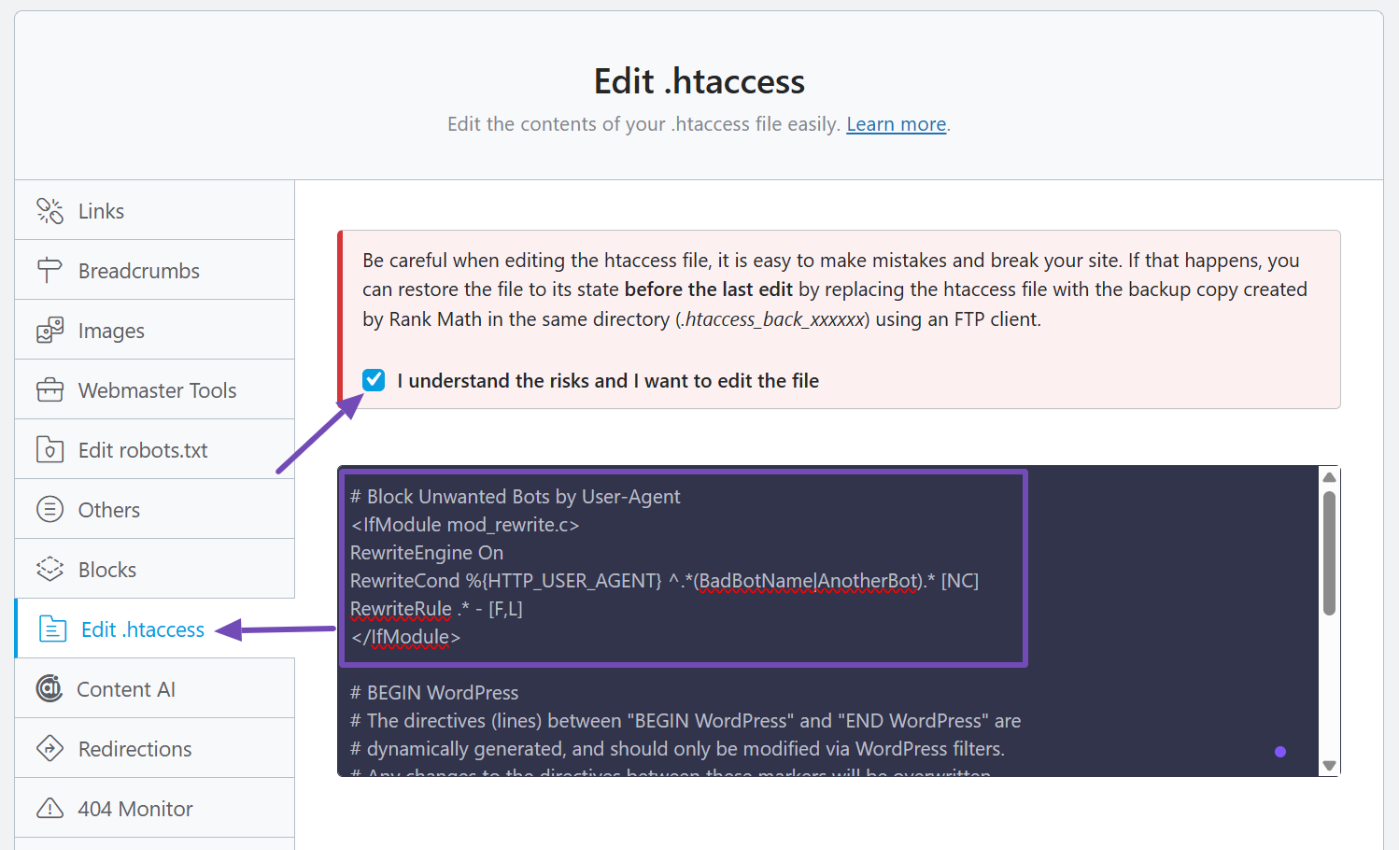
This code turns on the rewrite engine, checks if the visitor’s user-agent matches anything on your blocklist, and blocks them with a 403 Forbidden error. You can list multiple bots by separating their names with a | (pipe symbol).
Block Bots by IP Address
If you’ve found a suspicious IP or IP range in your log or maybe have one you got from a crawler’s documentation, you can block it directly with this:
# Block Unwanted Bots by IP
<Limit GET POST>
Order Allow,Deny
Allow from all
Deny from 192.0.2.123
Deny from 203.0.113.0/24
</Limit>Replace the sample IPs with the ones you want to block. Like before, place this code above the # BEGIN WordPress line, as shown below.
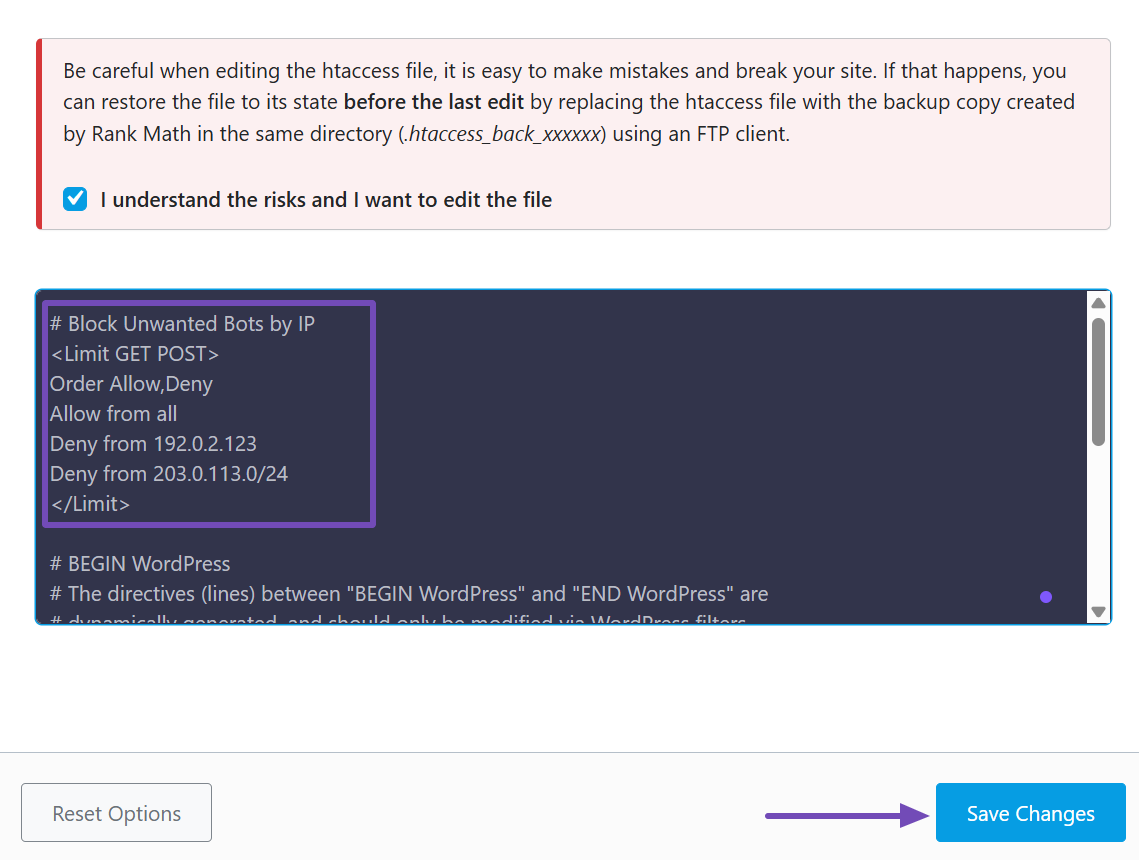
This approach is useful if the bot frequently changes its name (user-agent) but originates from the same IP range.
Once you’ve added your rules, don’t forget to save your changes.
4.3 Block AI Bots via Cloudflare
The rise of generative AI has increased the demand for content that can be used to train large language models (LLMs). As a result, many websites are now being crawled by AI bots, some that follow your rules, and others that don’t.
Cloudflare recently revealed that a growing number of AI crawlers are sending large volumes of requests to their users’ websites, with Bytespider and GPTBot making the highest number of requests, followed by other AI bots in the list.
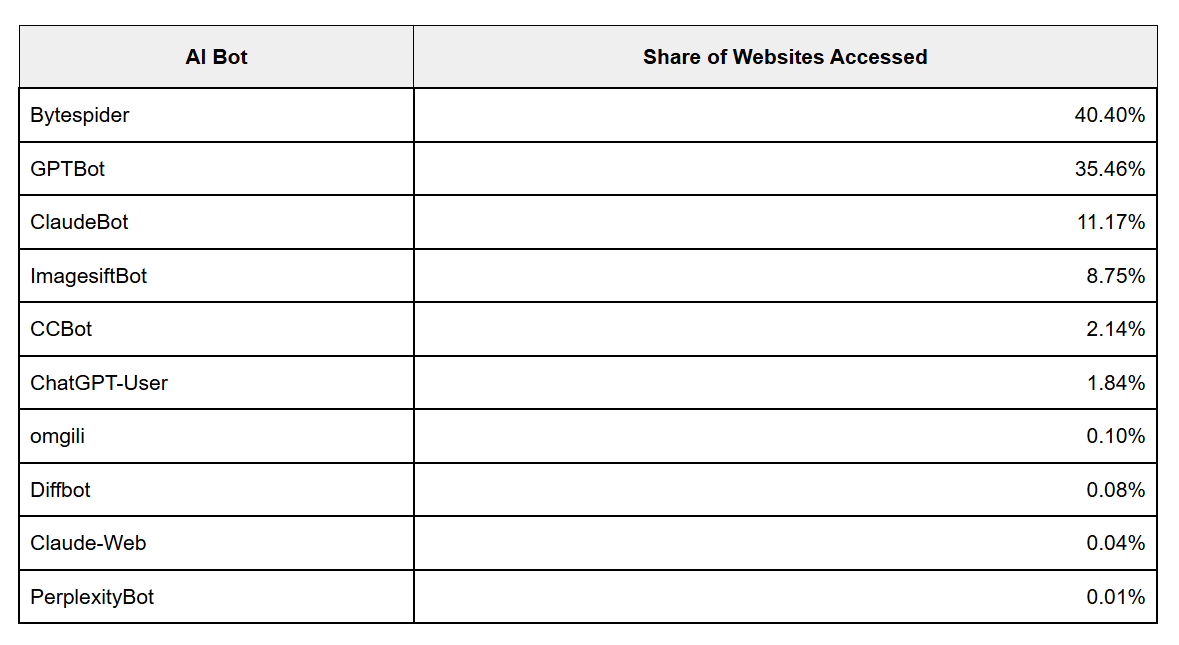
Although a few of these AI platforms respect robots.txt, not all of them do. And if you don’t want your content being used to train AI models, especially without your consent, you can block them directly in Cloudflare.
If your website is already connected to Cloudflare, here’s how to block them:
Log in to your Cloudflare dashboard and go to your site. From the menu, navigate to Security → Settings and scroll down to the Block AI bots section.
Click the pencil icon to edit the setting. When the side panel opens, select Block on all pages and then click Save.
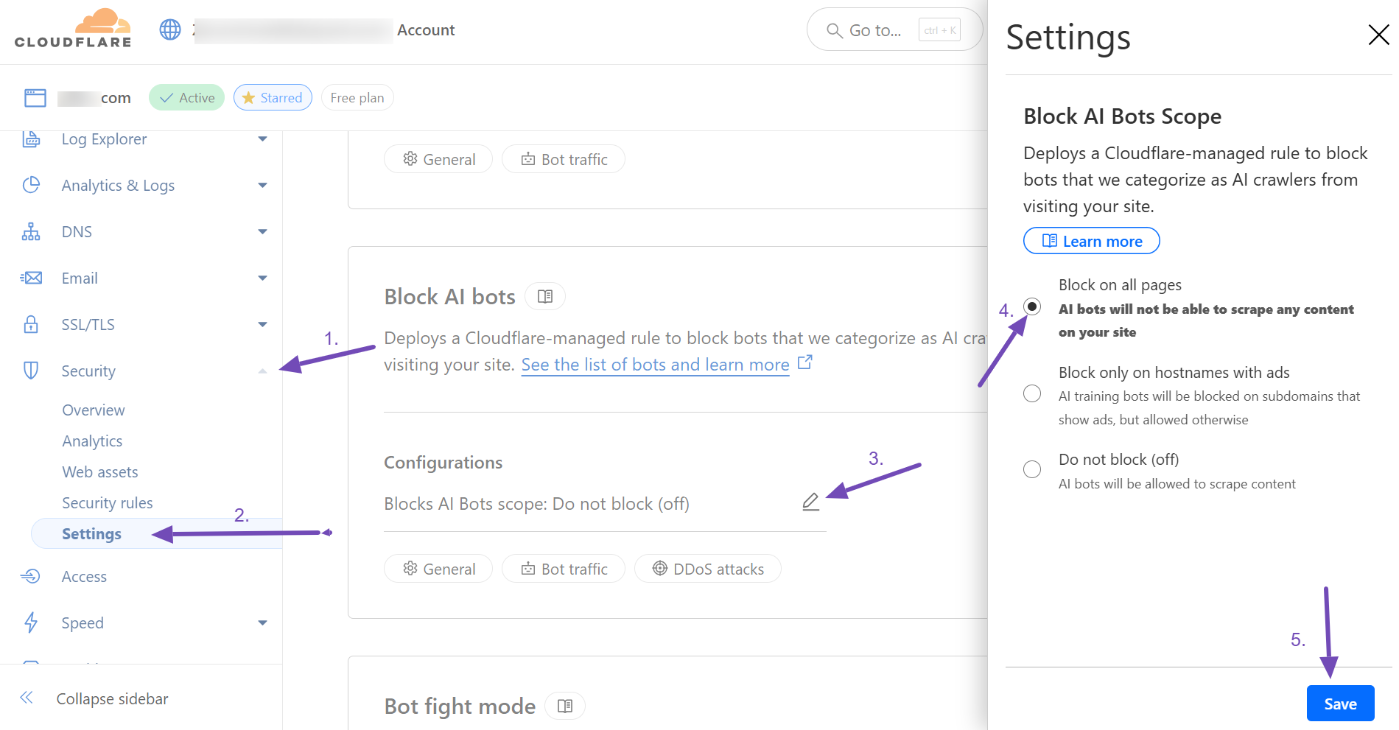
Once this is enabled, Cloudflare will automatically block all crawlers it categorizes as AI bots from accessing your site.
If you want more control, you can go to the AI Audits section in your Cloudflare dashboard. There, you’ll see a list of popular AI crawlers.
For any specific bot you want to block, such as Amazonbot or Applebot, you can manually switch its action to Block, as shown below. This feature is currently in beta, but it is already quite useful.

So, we’ve just covered the best ways to block unwanted web crawlers or bots from crawling or accessing your website. You can go with any method that suits you—they’re all simple to implement.
Other effective options include installing a security plugin with a built-in Web Application Firewall (WAF) or using CAPTCHA and honeypots on your forms. Tools like Google reCAPTCHA or Cloudflare’s Bot fight mode can help with that, too.
Just don’t forget: avoid blocking useful web crawlers, such as search engine bots. And make it a habit to monitor your logs regularly so you can spot and block any new unwanted bots.
Now, let’s look at some common questions you might have.
5 Frequently Asked Questions
How do I block web crawlers from accessing my entire website?
You can use Rank Math to add this code to your robots.txt file:User-agent: *
Disallow: /
This blocks all bots that follow the rules outlined in robots.txt. For stricter protection, use .htaccess or a firewall.
What’s the difference between a web crawler and a web scraper?
A web crawler browses websites to index their content, primarily for search engines. A web scraper extracts specific data (like text, prices, or images) from websites, often without permission.
Crawlers aim to understand your site; scrapers aim to copy from it.
Is web crawling legal?
Web crawling is generally legal when done responsibly, especially by search engines and tools that follow robots.txt rules. However, crawling becomes illegal if it violates a site’s terms of service, bypasses security, or causes harm (like overloading servers).
Does blocking web crawlers affect SEO?
Yes. Blocking search engine crawlers like Googlebot or Bingbot can prevent your site from being indexed or ranked. Only block bots you’ve confirmed are harmful or unnecessary.
How do I block the OpenAI web crawler?
To block OpenAI’s crawler (GPTBot), add this to your robots.txt file:User-agent: GPTBot
Disallow: /
You can do this easily in WordPress using Rank Math’s robots.txt editor.
And that’s it! We hope this guide helped you understand how to block unwanted web crawlers from accessing your site. If you have any questions or need assistance with Rank Math, feel free to reach out to our support team. We’re here for you 24/7, every day of the year.