When optimizing your website for search engines, you may face crucial decisions in controlling how search engines interact with your website content.
Among the commonly used directives for managing search engine indexing are noindex and robots.txt. Although both are critical in guiding search engine crawlers, they have different purposes and are applied under different circumstances.
In this knowledgebase article, we will explore noindex and robots.txt, providing insights into their differences and offering guidance on when to use each.
Understanding No Index
No Index is a rule that is set using <meta> tag or an HTTP response header. It is used to prevent search engines from indexing web content.
In simpler terms, the noindex meta tag is like telling search engines, “Hey, don’t show this page in search results.” When Googlebot or other crawlers find this tag in a page’s code, they’ll exclude that page from search results, even if other sites link to it.
The most common way to implement this rule is by adding an HTML <meta> tag attribute to your site, often placed in a page’s <head> section. It usually looks something like this:
<meta name="robots" content="noindex">Now, instead of dealing with the hassle of manually editing the <head> of your WordPress website, you can make things easier by using the Rank Math noindex feature. You can find more details about it here.
Understanding robots.txt
The robots.txt file guides search engine crawlers on the pages or files they can access on a website. It’s usually located at the website’s root and outlines the pages they can explore and those they should avoid.
Picture robots.txt as a road map for search engine crawlers, redirecting them away from private or sensitive sections while pointing them toward the content you want them to prioritize.
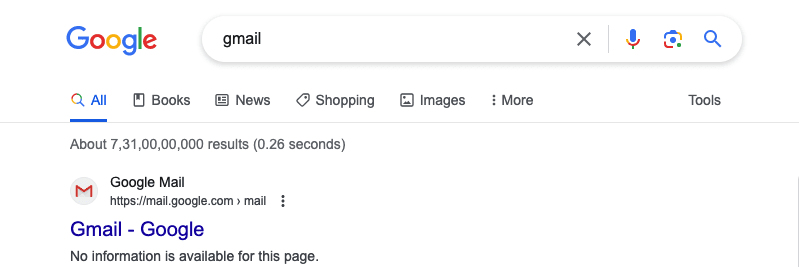
Remember, having a robots.txt file won’t prevent your page from appearing in search results, but will appear without a description.
That’s why you might sometimes see the message “No information is available for this page” on search results.
When you apply the noindex or robots.txt rules to a page, it affects not only the HTML content but also other non-HTML files such as images, videos, PDFs, etc. However, other pages or users can still access these files even with these rules.
Now that you’ve understood how noindex and robots.txt work, let’s consider when to implement these rules.
When to Use No Index
Here are some ways the noindex rule is used:
- The noindex rule can keep temporary pages off search engine results, like promotional landings or seasonal offerings.
- It helps prevent irrelevant pages from cluttering search results, like ‘Thank You pages’ post-purchase or subscription confirmations.
- When dealing with potential SEO problems tied to duplicate content, implementing noindex helps to signal to search engines which version deserves priority.
- The noindex rule can also protect sensitive information, author info, or restricted content from public exposure through search engines.
Once you’ve applied the noindex on your webpage, run it through the Google URL Inspection tool to ensure the HTML Googlebot receives during crawling is accurate.
Additionally, keep an eye on the Page Indexing report in the Search Console to track pages where Googlebot picked up a noindex rule.
When to Use robots.txt
Utilizing the robots.txt rule is a smart move to keep search engines from indexing specific sections of your website, like admin panels or private content. Additionally, you can guide search engine crawlers to your site’s sitemap and crucial pages.
Robots.txt also controls how search engines engage with your site, allowing you to set crawl delays or specify particular user-agents. This involves using directives “Allow” and “Disallow” to instruct search engines on which pages and files to crawl or skip.
For example, the default robots.txt for WordPress usually looks like this:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpLet’s explain these terms for better understanding:
- User-agent specifies the user-agent (search engine bot) the rule applies to. The asterisk (*) serves as a wildcard, meaning the rule covers all user-agents.
- Disallow points out the directories or pages the specified user-agent shouldn’t crawl. In the given example, “/wp-admin/” is off-limits.
- Allow grants access to specific directories or pages. In this case, “/wp-admin/admin-ajax.php/” is open for crawling.
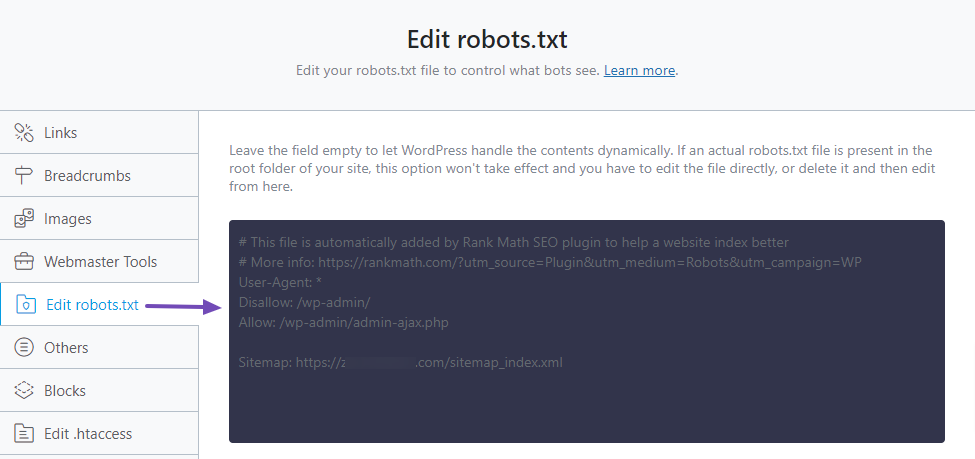
While WordPress doesn’t directly allow you to edit the robots.txt file, you can easily do so using Rank Math’s ‘Edit robots.txt’ setting on your WordPress dashboard by following this tutorial.
.
Having known the various ways you can implement the noindex and robots.txt rules on your website, let’s move on to the difference between them.
Differences Between No Index and robots.txt
Here are the main differences between noindex and robots.txt:
- noindex keeps specific pages out of search engine results, while robots.txt manages crawler access to the entire site.
- noindex is embedded in the HTML of individual pages, whereas robots.txt is a distinct file at the root level of your website.
- If a web page is blocked by a robots.txt file, its URL might still show up in search results. In contrast, with noindex, the page won’t appear in search results.
Note: To ensure the noindex rule works, remember two things: the page shouldn’t be blocked by robots.txt and must be reachable by the crawler. If it’s blocked or not reachable, the noindex rule won’t work, and the page can still appear in search results if other pages link to it.
We hope this article helped you understand noindex and robots.txt, elucidating their differences and guiding you on when to apply each.
If you have any questions, feel free to reach out to our dedicated support team—they’re available 24/7, 365 days a year.