What is a Noindex Tag?
The noindex tag is an HTML meta tag that instructs search engines not to index a page. Pages that are not indexed cannot appear on search results pages. Therefore, the noindex tag prevents webpages from appearing on search results pages.
Indexing is the process of saving a page to a database. These pages can then be displayed on Suchergebnisseiten. However, most site owners would have a few pages they would not want on search results pages for one reason or another.
For example, many site owners would not want search engines to index their login and checkout pages, so they add a noindex tag to the page’s head element.
<meta name="robots" content="noindex">
They can also specifically direct the noindex tag to a specific crawler. For example, the noindex tag below specifically disallows Googlebot from crawling the page.
<meta name="googlebot" content="noindex">
Once done, search engines will discover the noindex tag while crawling and know the site owner does not want them to display the page on search results pages. So, while they would crawl the page, they would not index or display it on their results pages.
The noindex meta tag is one of the methods of adding a noindex tag to a page. Another popular method is to add the noindex tag below to the X-Robots-Tag in your HTTP header.
X-Robots-Tag: noindex
Importance of the Noindex Tag
The noindex tag gives you control over the content search engines display on their results pages. Specifically, it allows you to prevent search engines from indexing pages you do not want on search results pages.
Von der SEO perspective, site owners use the noindex tag to prevent search engines from indexing thin content pages. This includes archives, internal search results, and thank you pages, which are typically low quality and offer no benefits to the visitor.
Site owners also use the noindex tag to prevent pages that contain sensitive or private content from appearing on search results pages. For example, login pages, checkout pages, and pages containing an online course or pages from a staging site.
This helps to preserve your Crawl-Budget as it ensures that search engines do not waste it crawling sensitive or unhelpful pages. It also improves your site’s SEO and ensures only high-quality content gets on search results pages.
Difference Between the Noindex Tag and robots.txt File
The noindex tag and robots.txt-Datei both control how search engines crawl the pages on a site. However, while the robots.txt file specifies the directories and folders search engines are not allowed to crawl, the noindex tag indicates the webpages search engines should not index.
It is important to note that the noindex tag prevents indexing while the robots.txt file prevents crawling. This means search engines can still crawl URLs containing the noindex tag. However, they would not index it.
The noindex tag is more effective at preventing indexing than the robots.txt file because search engines can discover your URLs by following interne Links on your site or from external sites. In such cases, they may index and display the page on search results pages without checking your robots.txt file.
However, if the page contains a noindex tag, search engines will detect the tag during crawling and will not index the page.
Noindex Tag Best Practices
The noindex meta tag can have serious SEO consequences when used improperly. It can prevent your important pages from appearing on search results pages and cause the not-so-helpful ones to appear. Here are some best practices to remember when using the noindex meta tag on your pages.
1 Do Not Disallow Your Pages Using the robots.txt File
Some site owners use the disallow rule in their robots.txt file to prevent search engines from crawling certain pages. For example, they could include the rule below to stop search engines from crawling the URL at yourdomain.com/yoga-for-beginners.
Disallow: /yoga-for-beginners
This may not work, as search engines can still find that page through other means and may crawl it without checking the robots.txt file. Once that happens, the page would appear on search results since it does not contain a noindex meta tag.
2 Do Not Include the Noindex Tag in Your robots.txt File
Some site owners include the noindex tag in their robots.txt file. For example, they may use the noindex rule below to prevent search engines from crawling and indexing the URL at yourdomain.com/yoga-poses-for-strength.
Noindex: /yoga-poses-for-strength
Google has clarified that it does not support the noindex tag in the robots.txt file. In other words, the tag does not affect how Google crawls or indexes the specified URL. So, it is recommended to avoid using this noindex rule in your robots.txt file.
3 Do Not Use the Noindex Tag on Duplicate Pages
Some site owners use the noindex tag to prevent Google from indexing their duplicate pages.
This is not recommended, as it could cause the site owner to lose the link equity und Seitenrang that points to and originates from such pages. It may also prevent the page that Google considers canonical from appearing on search results pages.
Instead of adding the noindex meta tag to your duplicate pages, specify the canonical URL Verwendung der canonical tag. This allows Google to identify which URL you want to use as canonical and appropriately distribute your PageRank and link equity.
4 Do Not Include the Noindex Tag on Your Category Pages
You should use the noindex tag on certain taxonomy pages. For example, many site owners set their tag pages to noindex since such pages typically contain thin and unhelpful content.
However, you should avoid using the noindex tag on your category pages. Category pages are crucial for SEO and should appear on search results pages. However, make sure to optimize them with relevant content, Schlüsselwörter, and internal links so that they are helpful to visitors.
5 Include Additional Directives With the Noindex Tag
You should use other directives with the noindex tag depending on how you want search engines to handle the page. For example, many site owners include the follow attribute in the noindex tag.
<meta name="robots" content="noindex, follow">
This ensures such pages can still pass link equity and PageRank even though they are set to noindex. It also assures them that search engines can follow such links to discover other important pages.
Similarly, some site owners include the nofollow attribute to manage link equity and prevent search engines from discovering other unhelpful or sensitive pages.
<meta name="robots" content="noindex, nofollow">
However, you should check with your search engine to understand how the additional attributes work. For example, there are concerns that Google does not follow the links on pages with a noindex tag. So, it would treat all links on noindex pages as nofollow, even if the blogger set them to follow.
6 Validate Your Noindex Tag
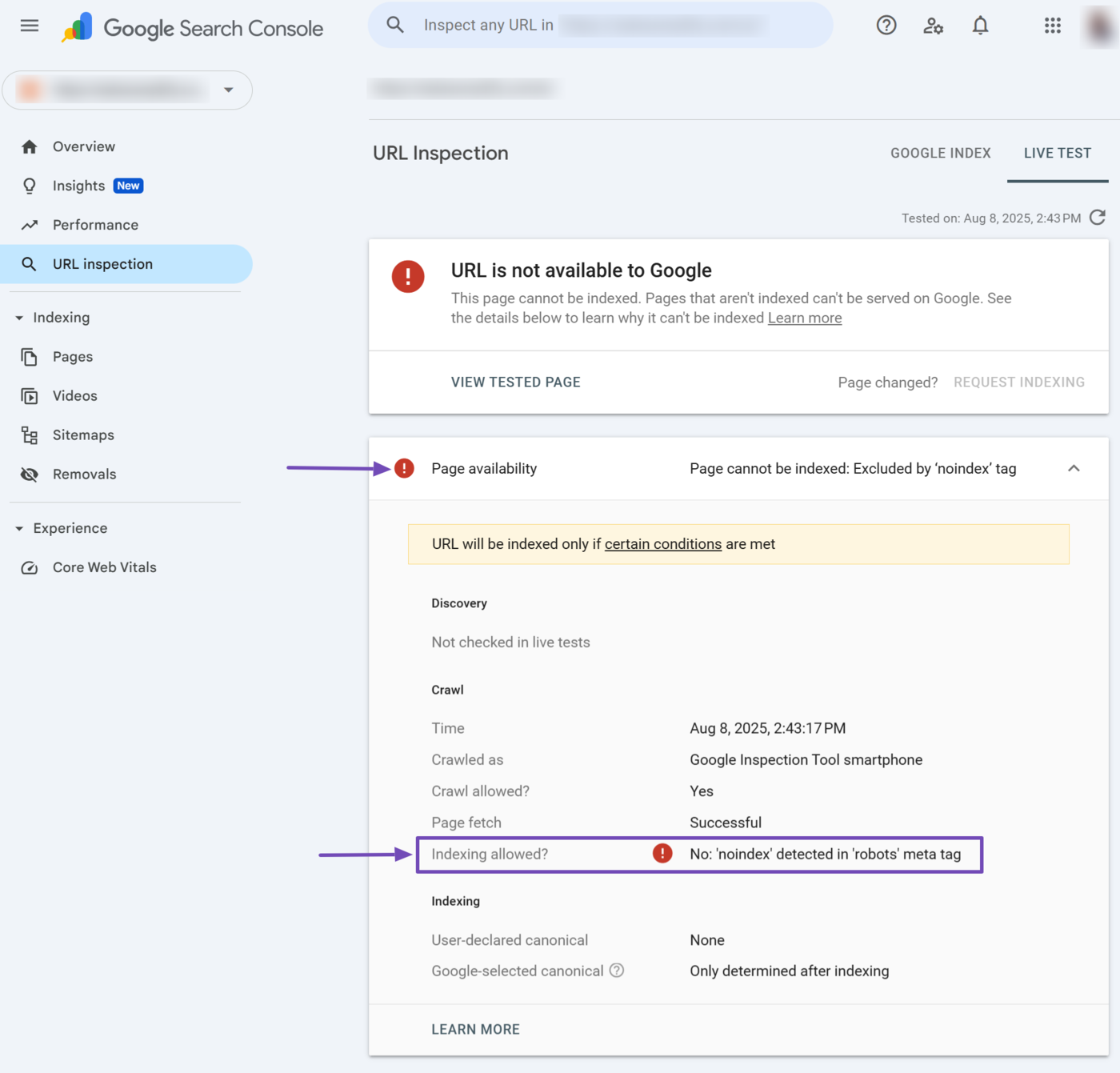
It is recommended to test your noindex tags to ensure they are working properly. A great way to do this is to enter the URL into the URL inspection tool in Google Search Console.
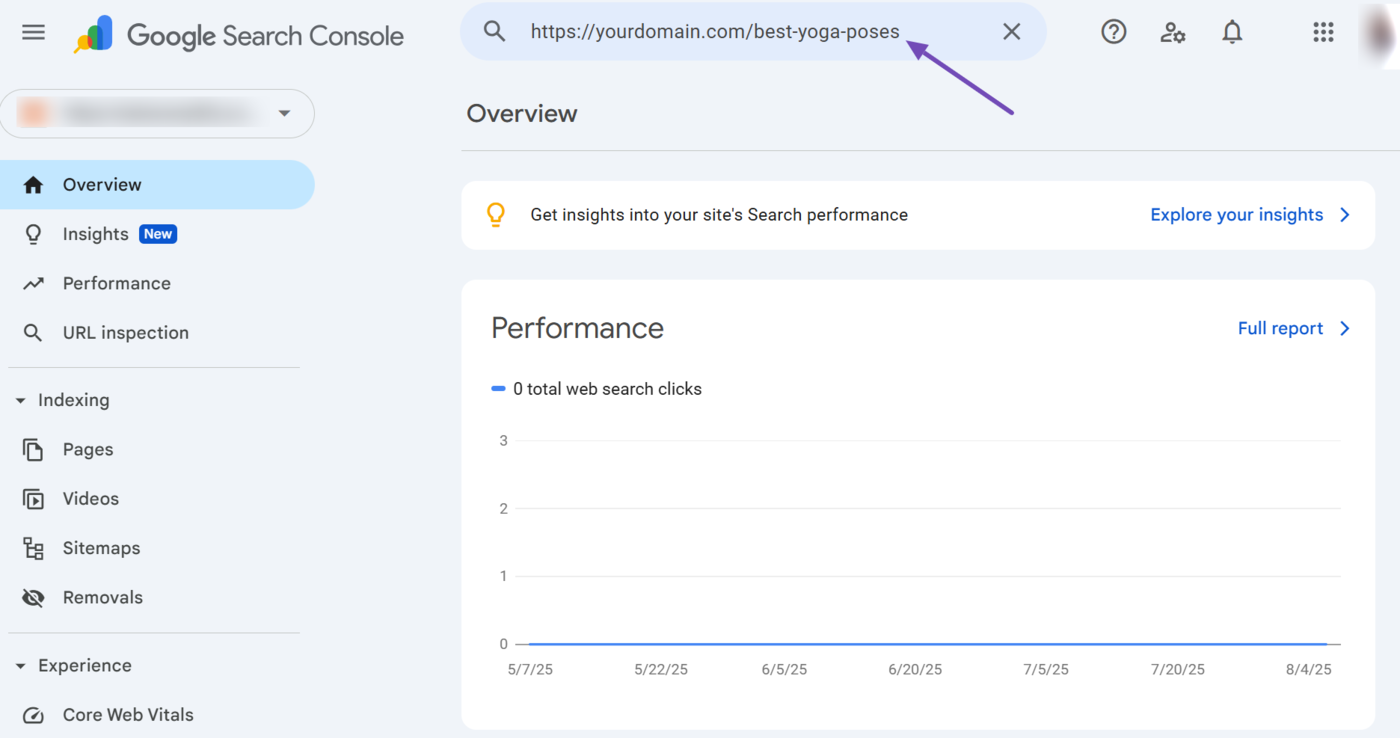
Next, click Live-URL testen.
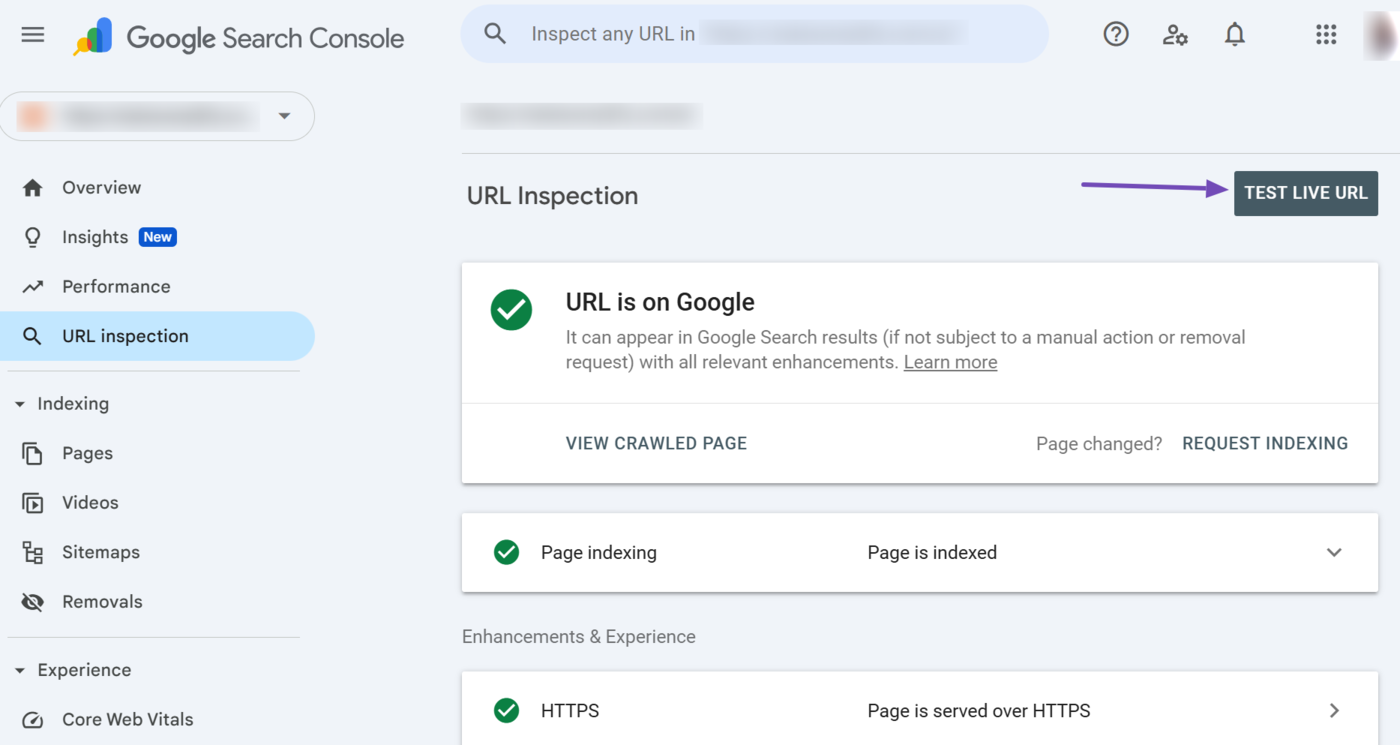
Once done, head to the Page availability → Indizierung erlaubt?. It should indicate a No: ‘noindex’ detected in ‘robots’ meta tag message, as shown below. This confirms there is a noindex tag on that webpage.