What Is Crawling?
Crawling in SEO is the process where search engine crawlers (also called bots or spiders) browse the web to discover new and updated webpages.
These crawlers discover new URLs by following links on webpages they have already found. For previously discovered URLs, they revisit them periodically to check for updates since their last crawl. If they have, they may then proceed to re-crawl it.
In this article, we’ll cover:
Importance of Crawling
Crawling is the first step search engines take to discover new and updated webpages they may want to show to their users. Crawling itself is intended to gather information about the webpage and determine whether it should be indexed.
Crawling is the first step of the search process. The entire search discovery process involves three steps, including:
- Krabbelnd
- Indexing
- Serving
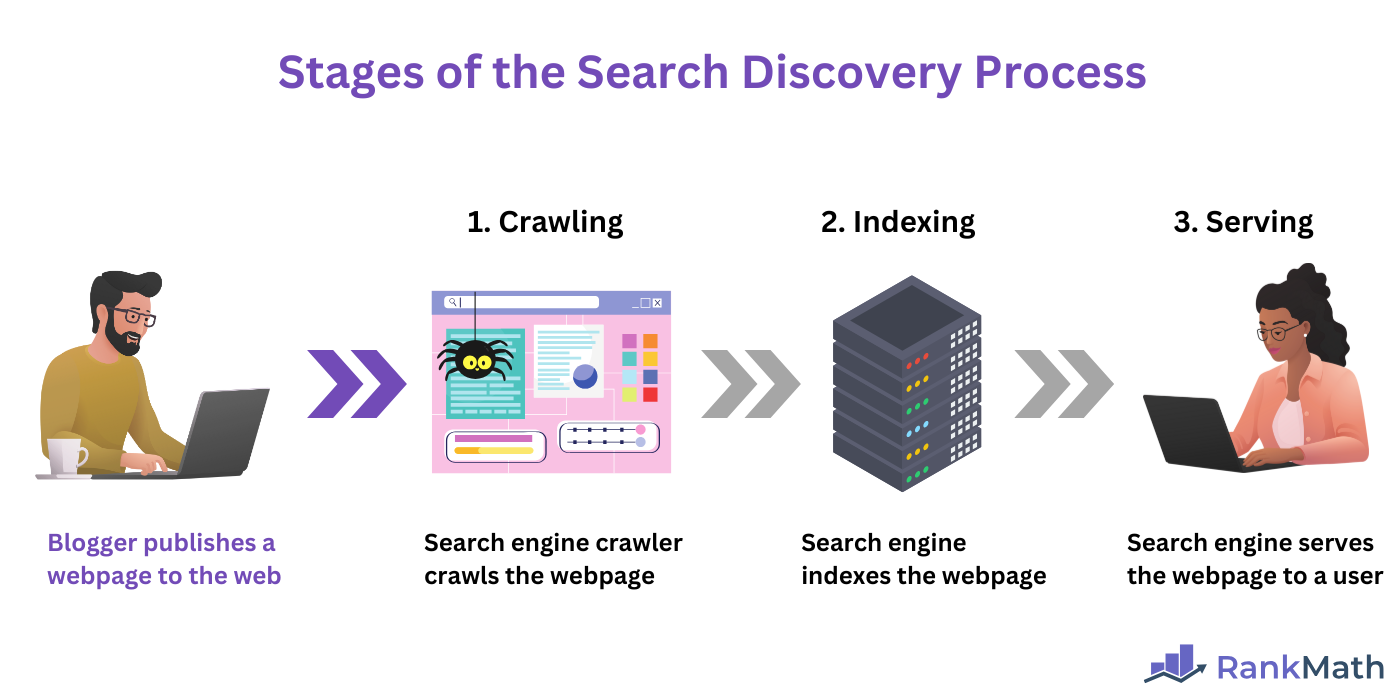
In summary:
- Crawling is the process by which a crawler discovers new or updated pages on the web
- Indexing is the stage where the discovered webpages are stored in a database called an index
- Serving occurs when the search engine retrieves relevant results from its index and displays them to a user in response to their search query
In all, crawling is crucial for indexing and serving to occur. Webpages that are not crawled are unlikely to be indexed. And webpages that are not indexed cannot appear on Suchmaschinen-Ergebnisseiten (SERPs).
What Is Crawlability?
Kriechbarkeit refers to a search engine’s ability to crawl a webpage.
Crawlability is closely related to crawling, as a URL with poor crawlability has a lower chance of being crawled. Even when crawled, it may not be crawled completely, which means some of its content will be missing from the index (database) and search results page.
This makes crawlability an essential aspect of Suchmaschinenoptimierung (SEO). As a rule, your URLs should have good auf Seite SEO, off-page SEO, und technisch SEO, as they directly impact crawlability.
Factors Affecting Crawling
Various factors determine a crawler’s ability to find, access, and crawl your URLs. These factors can be collectively grouped into various categories, including:
- Technisches SEO
- Crawl budget
- Crawl directives
- On-page and off-page SEO
Let us explain the ones we mentioned above one after another.
1 Technisches SEO
Technisches SEO is the process of optimizing your website’s code and infrastructure to ensure that users can access it and crawlers can crawl, index, and serve its URLs effectively.
Technical SEO has a profound and direct impact on your site’s crawlability. As a matter of fact, most crawling issues stem from technical SEO problems in your site’s code, server, or content delivery network (CDN).
Technical SEO issues that prevent the crawler from accessing a URL are generally referred to as crawl errors. Some technical SEO issues that can affect crawlability include:
- Broken links
- Server errors
- Redirect loops
- Redirect chains
- Slow site speed
a. Broken Links
A broken link occurs when a missing webpage leads to a 404 Not Found error. Such a webpage is missing from the site, either because its URL was changed (and was not properly umgeleitet) or it was deleted from the web.
In either case, the crawler cannot find the page, which means it cannot crawl it.
b. Server Errors
A server error occurs when the server fails to respond to the crawler’s request. This can be caused by downtimes or result from other errors on the server.
Server errors typically return 5xx series error codes, such as the 500 Interner Serverfehler und das 502 Bad Gateway error.
c. Redirect Loops
A redirect loop occurs when a URL redirects the crawler to another URL, which redirects the browser back to the initial URL.
This creates a loop where the crawler continually redirects to the same sets of URLs without being able to access the content. For example, URL A redirects to URL B, which redirects back to URL A.
d. Redirect Chains
A redirect chain occurs when a URL redirects to another URL, which then redirects to a second URL, which redirects to a third URL, and so on.
A redirect chain may ultimately lead to a final URL containing the desired content. However, search engines may not discover the content as they stop crawling a redirect chain after encountering a few redirects.
e. Site Speed
Sites and pages with low page speed are less likely to be crawled than those with a higher page speed. This can occur when the slow page speed prevents the crawler from accessing the webpage.
The slow site speed may also signal to search engines that your site has a limited server capacity, which can cause the search engine to reduce the rate at which it crawls your site.
2 Crawl-Budget
Die Crawl-Budget is the number of pages a search engine crawler will crawl on your site within a specific timeframe. You have no control over your crawl budget, as search engines are responsible for assigning one to you.
However, you may find yourself in situations where your crawl budget is not enough for your site. This can leave your important webpages uncrawled and unindexed, meaning they do not appear in search results pages.
The crawl budget is primarily a technical SEO issue, but various on-page SEO issues can also impact it.
Overall, you should ensure to use canonical tags so that search engines can correctly identify the most preferred among a group of similar and duplicate webpages.
You should also set low-value dynamic URLs, such as those with calendars and session IDs, to noindex so that they do not consume your crawl budget.
You should also ensure your URLs are always available, as repeated client errors, such as the 429 Too Many Requests error, and server errors, such as the 500 Internal Server error, can cause the search engine to reduce your crawl budget.
3 Crawl Directives
Bloggers sometimes set directives that instruct search engines how to crawl their URLs. These directives are collectively referred to as crawl directives and encompass a combination of on-page SEO and technical SEO.
Bloggers can set crawl directives using the:
Let us briefly explain them.
a. robots.txt File
The robots.txt file allows you to tell search engines which parts of a website they are allowed or not allowed to access and crawl.
This allows you to control how search engines crawl your links. Specifically, you can use it to prevent them from crawling low-quality and private pages, which increases their chances of crawling the important ones.
b. Noindex Tag
The noindex tag is a meta tag that instructs search engines not to include a specific page in their search index. While search engines may still crawl such URLs, they do not Index them, which means they do not appear on search results pages.
You can add the noindex tag directly to your webpage’s code. Optionally, you can add it to the X-Robots-Tag of your HTTP header.
c. Nofollow Tag
The nofollow tag tells search engine crawlers not to follow a specific link.
While considered a crawl directive, the nofollow tag does not outright block search engines from crawling the URL. Instead, it discourages them from crawling or passing link equity und Seitenrang to the URL.
4 On-Page and Off-Page SEO
Search engines discover new URLs by following the URLs on previously discovered webpages. This makes hyperlinks a crucial aspect of crawling.
URLs that do not have any interne Links (on-page SEO) or backlinks (off-page SEO) pointing to them will likely remain undiscovered. Such pages are called verwaiste Seiten and are, for the most part, invisible to search engines.
Similarly, other on-page SEO factors can impact crawling. For instance, a search engine may refuse to crawl thin content or duplicate content even after discovering it.
This happens because the search engines believe such content is not valuable for their index or audience, so they do not bother to crawl at all. Even when they crawl it, they may refuse to index it.