What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a generative AI framework that combines a large language model with an external retrieval system. This enhances the AI’s response by allowing it to include additional information that is not part of its training data.
In generative AI, a large language model (LLM) is a system trained on large amounts of data and able to process, understand, and generate human-like content, including text, images, and code.
Every standard AI system, including Google’s AI Mode, Microsoft’s Copilot, e OpenAI’s ChatGPT, is powered by a large language model.
Meanwhile, the external retrieval system is a database outside the large language model. This database could be a private or publicly available one. In the case of search engines, it could be the search engine index.
For example, Google’s AI Mode, AI Overviews, and the Gemini chatbot combine the Google Search index with the Gemini large language model. Similarly, Microsoft’s Copilot integrates with the Bing Search index and the GPT large language model.
Most modern generative AI systems utilize retrieval-augmented generation. Specifically, AI answer engines (such as AI Mode and Perplexity) are typically built with retrieval-augmented generation capability, while AI chatbots (such as Gemini and ChatGPT) often incorporate search features that implement retrieval-augmented generation.
In questo articolo tratteremo:
How Retrieval-Augmented Generation Works
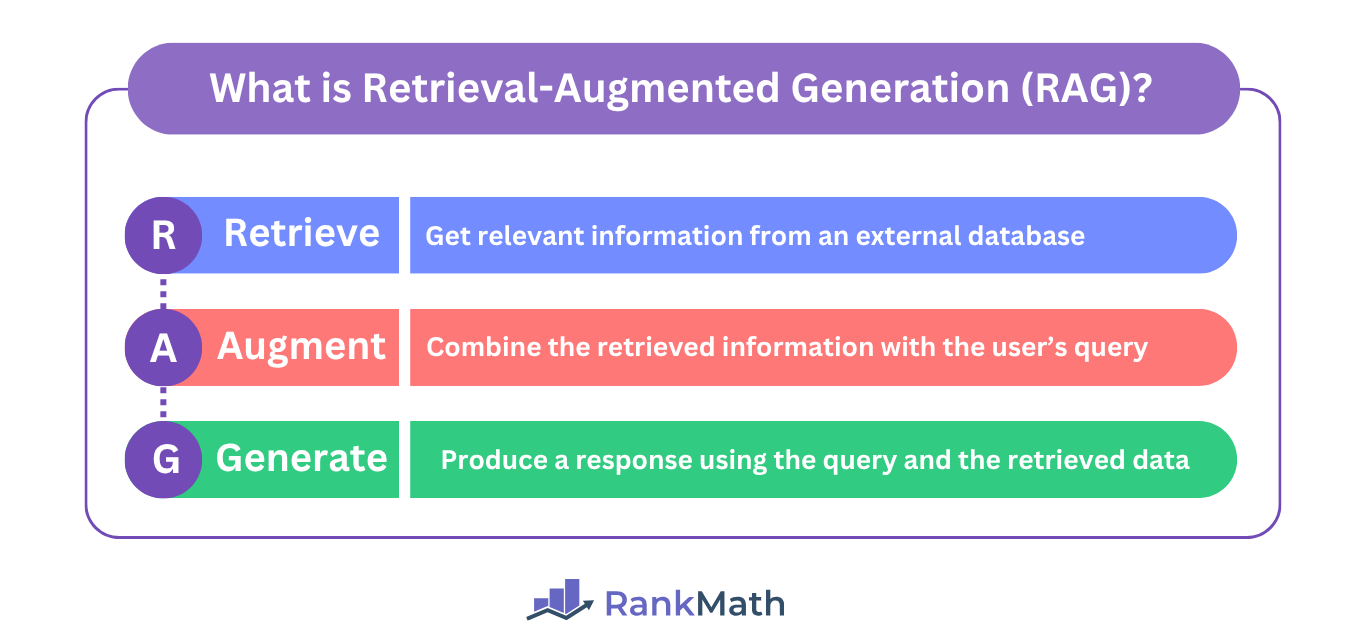
Retrieval-augmented generation (RAG) is a two-step process involving:
- Retrieval
- Generation
That is, it involves retrieving data from an external data source and then generating a response, which is then returned to the user.
Nota: An AI search engine or chatbot that does not implement RAG skips the retrieval step and generates a response without accessing any external database.
Here is a rundown of how retrieval-augmented generation works:
- The user enters a query di ricerca into the AI chatbot or AI search engine (called an answer engine)
- The AI system sends the query to a retrieval component, such as a search engine index
- The retrieval component returns the most relevant data or documents to the AI system
- The AI system combines this retrieved data with the original query to create an enhanced prompt
- The large language model then generates an output for the user
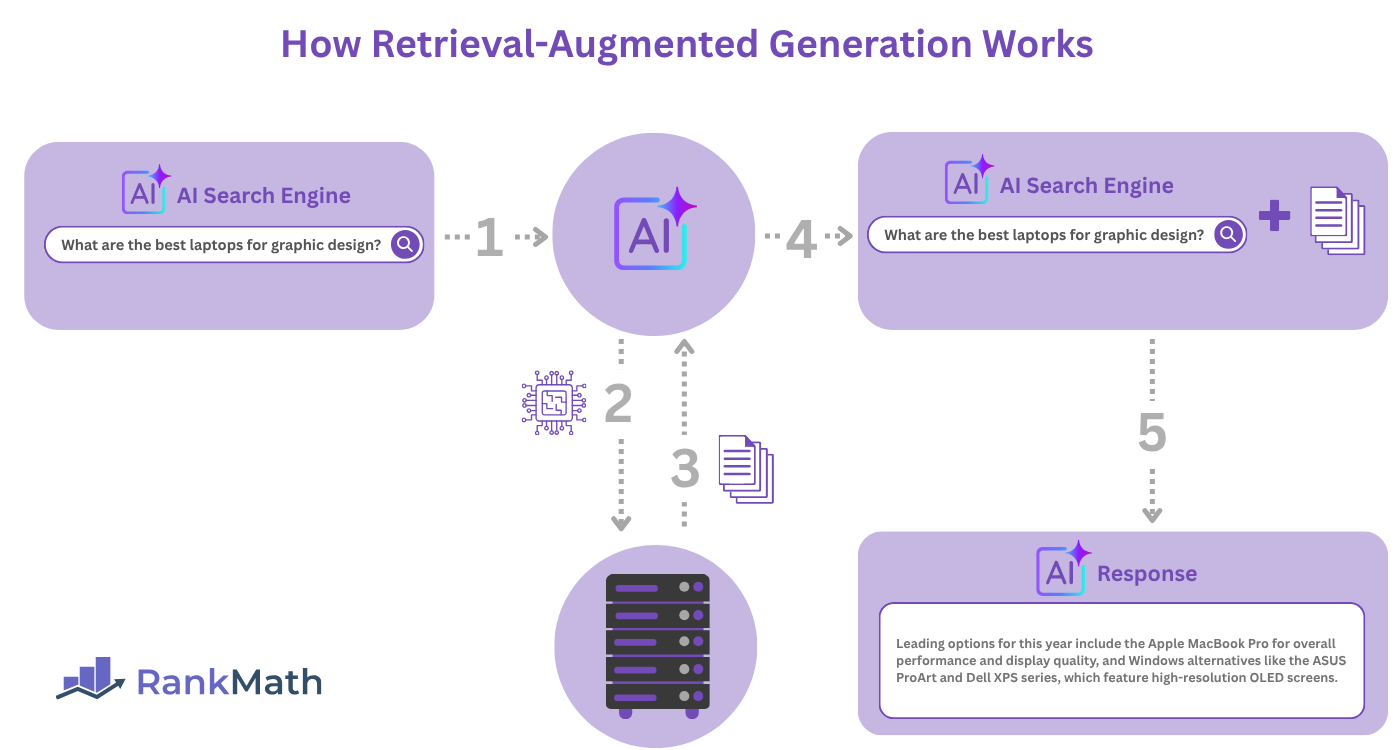
When a user enters a prompt into such an AI system, the system first retrieves relevant information from a database before passing the prompt and retrieved data to the large language model (LLM). The large language model then uses the retrieved data, alongside its own training data, to generate a response.
With that said, let us explain the retrieval aspect in more detail.
How Retrieval Works in Retrieval-Augmented Generation
When a user enters a prompt into the AI search engine or chatbot with search capability, the AI system proceeds to retrieve relevant information from an external database.
The external database from which the generative AI system retrieves data can be open-source, such as websites on the web, or a closed system, such as databases accessible only to authorized individuals, such as employees in a company.
In the case of search engines, this external database is typically the search engine’s index. However, depending on the query, it can also be a third-party database (such as in the case of live scores of a game).
For example, Google’s generative AI systems (AI Mode, AI Overviews, the Gemini chatbot) retrieve data from Google Search’s index (a public database) while Microsoft’s Copilot retrieves data from the Bing Search index.
Many private chatbots, such as those used by businesses, can access internal webpages, documents, and private databases.
Once done, the AI system proceeds to pre-preprocess the retrieved data. This means it tokenizes, stems, and removes stop words from the retrieved data.
In artificial intelligence:
- Tokenization is the process of breaking sentences into words, subwords, or characters
- Stemming is the process of reducing words to their root or base form; for example, “running” can be stemmed into “run”
- Stop words are words that are frequently used in everyday language, even though they do not add meaningful value to the content. For example, “the”, “is”, and “and”
Once done, the AI system generates a response using its own large language model as well as the retrieved data.
Importance of Retrieval-Augmented Generation
Retrieval-augmented generation allows a generative AI system to access and extract data from an external source, rather than relying solely on the data on which it was trained. This allows the AI system to return relevant answers to the user’s queries, even when such data is absent from its own data.
This improves the accuracy and capability of the generative AI system. It also resolves multiple issues related to generative AI, such as the cut-off date problem, which refers to the inability of a large language model to access or generate information beyond the date it was last trained.
For example, an AI system with a cut-off date of January will be unable to answer questions about an event, such as a football match, that occurred in April of the same year. Similarly, the AI system cannot tell the weather or even the stock prices of the days following its cut-off date.
However, with retrieval-augmented generation, the AI system can access such information and then return it to the user.
How Google and Bing Use Retrieval-Augmented Generation
Google and Bing use retrieval-augmented generation (RAG) to improve the results their AI systems provide to their users. Both search engines have integrated various AI tools and features into their search results pages.
For instance, Google has:
- AI Mode (an answer engine)
- AI Overviews (a pagina dei risultati della ricerca feature)
- Gemini (an AI chatbot)
Similarly, Microsoft’s Copilot can function as an answer engine, an AI chatbot, or a search results page feature, depending on your query and how you access it.
Now, these systems will be unable to provide super-relevant responses to specific questions that a regular search engine would. For instance, they cannot provide answers to queries like:
- What was the score of the match played yesterday
- Show me a sushi restaurant near me
- What happened in the US yesterday
Similarly, they will be unable to provide responses to queries relating to issues beyond their cut-off date.
However, with retrieval-augmented generation, they will be able to retrieve relevant answers for such queries from relevant databases and include them in their responses.
Difference Between Retrieval-Augmented Generation and Semantic Search
Retrieval-augmented generation and semantic search are two retrieval techniques commonly used by search engines. Both systems retrieve information from a database and present it to the user. However, their purposes differ.
Semantic search retrieves the most relevant text or documents that semantically match a user’s query. That is, it finds text and documents that have the same meaning and context as the user’s query.
Semantic search focuses on finding and ranking information, rather than generating new content. So, the user typically accesses or uses the retrieved documents directly without any additional input from the search engine.
Retrieval-augmented generation, on the other hand, retrieves information from a database and passes it to a large language model, which then generates a response to the user.
In all, semantic search finds information and returns it to the user, while retrieval-augmented generation finds information and passes it through a large language model before returning it to the user.
Benefits of Retrieval-Augmented Generation
Retrieval-augmented generation improves a generative AI’s system ability to return relevant answers to users. This has multiple benefits for the AI system and its users.
1 It Turns Search Engines into Answer Engines
Retrieval-augmented generation effectively converts AI search engines and chatbots into answer engines. An answer engine is literally an AI-powered search engine.
Without retrieval-augmented generation, AI chatbots will be unable to provide information outside their training data to users. Meanwhile, AI-powered search engines will be unable to deliver real-time or up-to-date answers to their users.
2 It Improves Accuracy
Retrieval-augmented generation allows AI systems to incorporate the latest facts, discoveries, news, and updates into their responses. This is particularly useful in fast-changing niches, such as finance, health, or news, where users typically require factual and up-to-date information.
3 It Reduces Hallucination
Hallucination refers to the situation wherein an artificial intelligence model generates false or misleading information. This occurs when the AI model tries to answer a question using incomplete, outdated, or nonexistent information from its training data.
Retrieval-augmented generation reduces an AI’s ability to hallucinate, as the AI system can complement its data with that extracted by the system. This keeps its response up-to-date and reduces the impact of incomplete and outdated data on the response.
4 It Enables the Usage of Smaller AI Models
Retrieval-augmented generation systems allow businesses to use smaller AI models compared to standard generative AI systems without retrieval-augmented generation capabilities.
This is helpful for businesses that require a generative AI system but do not want to invest heavily in training or deploying large, resource-intensive models.
Instead of investing in a resource-intensive model, the business can rely on a smaller, less resource-intensive model with retrieval-augmented generation capabilities.
5 It Reduces the Size of the AI Model
Retrieval-augmented generation reduces the size of the AI model. This, in turn, reduces the resources required to create, train, and maintain it.
This works because retrieval-augmented generation enables the AI model to store data in an external database rather than its memory. This separation of storage from generation keeps the AI system lighter than it would otherwise be.
6 It Is Easier to Update
Retrieval-augmented generation makes it easy to update your generative AI system. Instead of retraining the AI model as you would with a non-RAG system, you only have to update the external database with the required information, and the AI will have access to it.
7 It Allows AI to Access Internal Data
Retrieval-augmented generation systems can be configured to only search within a specific data or knowledge base. This includes private databases that are not accessible to outsiders.
This is helpful as it allows the AI to access private information without compromising the data.
Without the retrieval-augmented generation system, the AI would have to store the data in its own memory, which leaves it vulnerable to data leaks, unauthorized access, and unintentional exposure of sensitive information to third parties or even the public.