Che cos'è lo strisciare?
Il crawling in SEO è il processo in cui i crawler dei motori di ricerca (chiamati anche bot o spider) esplorano il web per scoprire pagine nuove e aggiornate.
Questi crawler scoprono nuovi URL seguendo i link delle pagine web che hanno già trovato. Per quanto riguarda gli URL scoperti in precedenza, li rivisitano periodicamente per verificare la presenza di aggiornamenti dall'ultimo crawling. In caso affermativo, possono procedere a un nuovo crawling.
In questo articolo tratteremo:
L'importanza di strisciare
Il crawling è il primo passo che i motori di ricerca compiono per scoprire pagine web nuove e aggiornate da mostrare agli utenti. Il crawling in sé ha lo scopo di raccogliere informazioni sulla pagina web e determinare se debba essere indicizzata.
Il crawling è la prima fase del processo di ricerca. L'intero processo di ricerca comporta tre fasi, tra cui:
- Strisciare
- Indicizzazione
- Servire
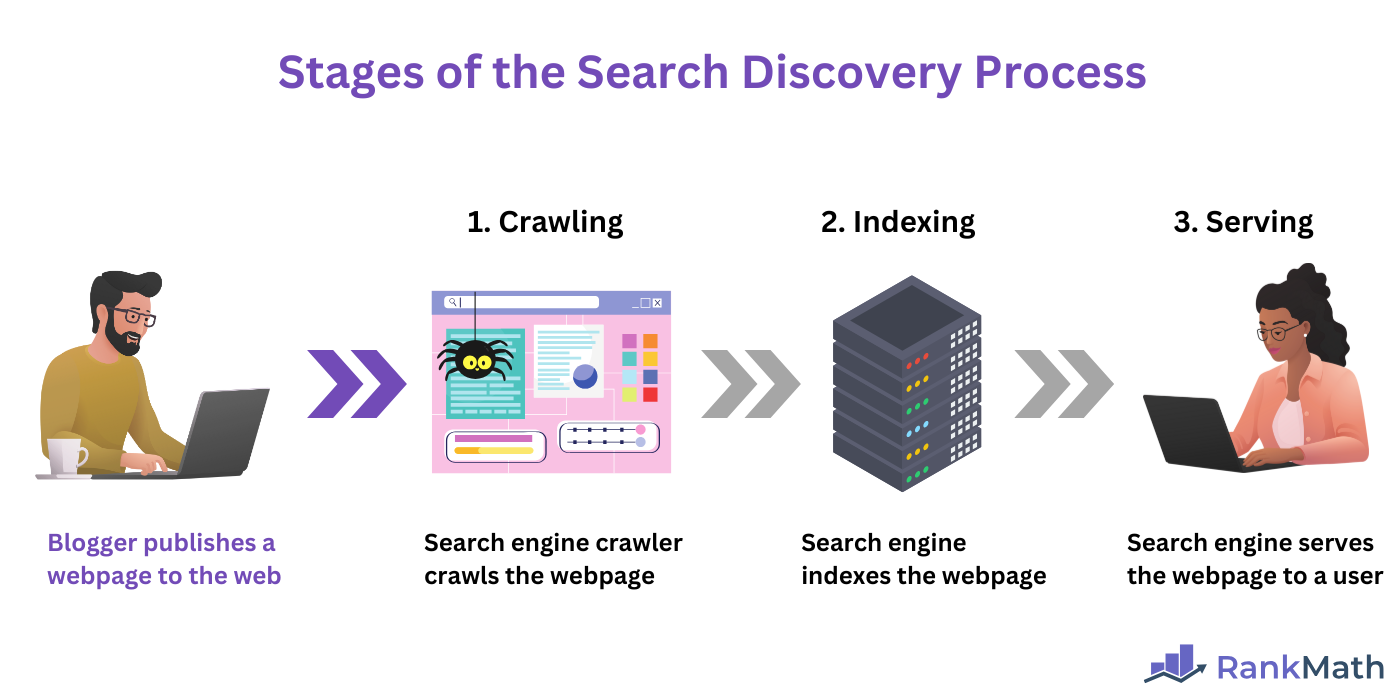
In sintesi:
- Il crawling è il processo attraverso il quale un crawler scopre pagine nuove o aggiornate sul web.
- L'indicizzazione è la fase in cui le pagine web scoperte vengono memorizzate in un sistema di database chiamato indice
- Il serving avviene quando il motore di ricerca recupera i risultati rilevanti dal suo indice e li mostra all'utente in risposta alla sua richiesta. query di ricerca
In generale, il crawling è fondamentale per l'indicizzazione e il servizio. È improbabile che le pagine web non sottoposte a crawling vengano indicizzate. E le pagine web che non sono indicizzate non possono apparire su pagine dei risultati dei motori di ricerca (SERP).
Che cos'è la crawlability?
Scansione si riferisce alla capacità di un motore di ricerca di effettuare il crawling di una pagina web.
La crawlabilità è strettamente correlata al crawling, in quanto un URL con scarsa crawlabilità ha minori possibilità di essere crawlato. Anche quando viene strisciato, potrebbe non essere completamente strisciato, il che significa che alcuni dei suoi contenuti mancheranno dal sito di indice (database) e la pagina dei risultati della ricerca.
Questo rende la crawlability un aspetto essenziale di ottimizzazione dei motori di ricerca (SEO). In linea di massima, gli URL devono avere una buona a pagina SEO, fuori pagina SEO, e tecnico SEOin quanto hanno un impatto diretto crawlability.
Fattori che incidono sul gattonamento
Vari fattori determinano la capacità di un crawler di trovare, accedere e scansionare i vostri URL. Questi fattori possono essere raggruppati in varie categorie, tra cui:
- Tecnico SEO
- Budget per le strisciate
- Direttive di crawl
- On-page e off-page SEO
Spieghiamo una dopo l'altra quelle che abbiamo citato sopra.
1 Tecnico SEO
Tecnico SEO è il processo di ottimizzazione del codice e dell'infrastruttura del sito web per garantire che gli utenti possano accedervi e che i crawler possano scansionare, indicizzare e servire efficacemente i suoi URL.
I problemi tecnici SEO hanno un impatto profondo e diretto sulla crawlabilità del sito. In effetti, la maggior parte dei problemi di crawling deriva da problemi tecnici nel codice del sito, nel server o nel sito stesso. rete di distribuzione dei contenuti (CDN).
I problemi tecnici SEO che impediscono al crawler di accedere a un URL sono generalmente indicati come Errori di strisciamento. Alcuni problemi tecnici SEO che possono influire sulla crawlability includono:
- Collegamenti interrotti
- Errori del server
- Loop di reindirizzamento
- Catene di reindirizzamento
- Velocità del sito lenta
a. Collegamenti interrotti
Un collegamento interrotto si verifica quando una pagina web mancante conduce a un Errore 404 non trovato. Una pagina web di questo tipo è assente dal sito, o perché il suo URL è stato modificato (e non è stato correttamente reindirizzato) o è stato cancellato dal web.
In entrambi i casi, il crawler non riesce a trovare la pagina e quindi non può effettuare il crawling.
b. Errori del server
Un errore del server si verifica quando il server non risponde alla richiesta del crawler. Questo può essere causato da tempi di inattività o da altri errori del server.
Gli errori del server restituiscono in genere codici di errore della serie 5xx, come ad esempio l'opzione 500 Errore interno del server e il errore di connessione 502 Bad Gateway errore.
c. Loop di reindirizzamento
Un ciclo di reindirizzamento si verifica quando un URL reindirizza il crawler a un altro URL, che reindirizza il browser all'URL iniziale.
In questo modo si crea un ciclo in cui il crawler viene continuamente reindirizzato agli stessi set di URL senza poter accedere al contenuto. Ad esempio, l'URL A reindirizza all'URL B, il quale reindirizza nuovamente all'URL A.
d. Catene di reindirizzamento
Una catena di reindirizzamento si verifica quando un URL reindirizza a un altro URL, che poi reindirizza a un secondo URL, che reindirizza a un terzo URL e così via.
Una catena di reindirizzamenti può portare a un URL finale contenente il contenuto desiderato. Tuttavia, i motori di ricerca potrebbero non scoprire il contenuto, in quanto smettono di effettuare il crawling di una catena di reindirizzamenti dopo aver incontrato alcuni reindirizzamenti.
e. Velocità del sito
Siti e pagine con bassa velocità della pagina hanno meno probabilità di essere crawlate rispetto a quelle con una velocità di pagina più elevata. Questo può accadere quando la bassa velocità della pagina impedisce al crawler di accedere alla pagina web.
La lentezza del sito può anche segnalare ai motori di ricerca che il vostro sito ha una capacità limitata del server, il che può indurre il motore di ricerca a ridurre la velocità di scansione del vostro sito.
2 Scansione del budget
Il scansionare il budget è il numero di pagine che un crawler dei motori di ricerca scansionerà sul vostro sito entro un determinato periodo di tempo. Non avete alcun controllo sul vostro crawl budget, poiché i motori di ricerca sono responsabili di assegnarvelo.
Tuttavia, potreste trovarvi in situazioni in cui il vostro budget per il crawl non è sufficiente per il vostro sito. Questo può lasciare le vostre pagine web importanti non scansionate e non indicizzate, il che significa che non appaiono nelle pagine dei risultati di ricerca.
Il budget di crawl è principalmente una questione tecnica, ma possono influire anche vari aspetti della pagina.
Nel complesso, ysi deve fare in modo di utilizzare tag canonici in modo che i motori di ricerca possano identificare correttamente il più preferito tra un gruppo di prodotti simili e pagine web duplicate.
Si dovrebbe anche impostare un valore basso URL dinamicicome quelli con i calendari e gli ID di sessione, da noindicizzare in modo che non consumino il budget per il crawling.
Dovete inoltre assicurarvi che i vostri URL siano sempre disponibili, poiché i ripetuti errori del client, come l'errore 429 Too Many Requests, e del server, come l'errore 500 Internal Server, possono indurre il motore di ricerca a ridurre il vostro budget di crawl.
3 Direttive di crawl
I blogger a volte impostano delle direttive che indicano ai motori di ricerca come effettuare il crawling dei loro URL. Queste direttive vengono chiamate collettivamente direttive di crawl e comprendono una combinazione di SEO on-page e SEO tecnico.
I blogger possono impostare le direttive di crawl utilizzando l'opzione:
Let us briefly explain them.
a. robots.txt File
The robots.txt file allows you to tell search engines which parts of a website they are allowed or not allowed to access and crawl.
This allows you to control how search engines crawl your links. Specifically, you can use it to prevent them from crawling low-quality and private pages, which increases their chances of crawling the important ones.
b. Noindex Tag
The noindex tag is a meta tag that instructs search engines not to include a specific page in their search index. While search engines may still crawl such URLs, they do not indice them, which means they do not appear on search results pages.
You can add the noindex tag directly to your webpage’s code. Optionally, you can add it to the X-Robots-Tag of your HTTP header.
c. Nofollow Tag
The nofollow tag tells search engine crawlers not to follow a specific link.
While considered a crawl directive, the nofollow tag does not outright block search engines from crawling the URL. Instead, it discourages them from crawling or passing link equity e PageRank to the URL.
4 On-Page e Off-Page SEO
Search engines discover new URLs by following the URLs on previously discovered webpages. This makes hyperlinks a crucial aspect of crawling.
URLs that do not have any internal links (on-page SEO) or backlink (off-page SEO) pointing to them will likely remain undiscovered. Such pages are called pagine orfane and are, for the most part, invisible to search engines.
Similarly, other on-page SEO factors can impact crawling. For instance, a search engine may refuse to crawl thin content or duplicate content even after discovering it.
This happens because the search engines believe such content is not valuable for their index or audience, so they do not bother to crawl at all. Even when they crawl it, they may refuse to index it.