Was ist BERT?
BERT, kurz für Bidirectional Encoder Representations from Transformers, ist ein Modell der künstlichen Intelligenz und ein Algorithmus für maschinelles Lernen die Google verwendet, um die Absicht einer Suchanfrage zu verstehen.
Google hat BERT als Open-Source-Projekt veröffentlicht im Jahr 2018. Vor BERT entdeckte Google die Suchabsicht durch die Analyse der Schlüsselwörter in der Suchanfrage. Mit BERT verwendet Google jetzt jedoch die Natural Language Processing (NLP)-Technologie.
Anstatt nur die Schlüsselwörter in der Suchanfrage mit den Schlüsselwörtern in den angezeigten Ergebnissen abzugleichen SuchergebnisseitenBERT identifiziert die entscheidenden Wörter in der Suchanfrage und nutzt sie, um den Kontext aufzudecken, in dem sie verwendet werden. Dies wiederum ermöglicht es Google, die Suchabsicht zu verstehen und im Gegenzug relevantere Ergebnisse zu liefern.
BERT ist kein generative KI wie ChatGPT oder ZwillingeBERT ist ein Sprachverständnismodell, das für Aufgaben wie Textklassifizierung, Fragenbeantwortung und Named-Entity-Erkennung entwickelt wurde. Es wird darauf trainiert, Text zu verstehen und zu verarbeiten, indem es maskierte Wörter in Sätzen vorhersagt, anstatt neuen Text zu generieren.
Generative KI-Modelle wie GPT erzeugen neue Inhalte durch die Generierung von Wortfolgen, Sätzen oder ganzen Dokumenten. Im Gegensatz dazu liegt die Hauptstärke von BERT in der Analyse und dem Verständnis vorhandener Texte, nicht in der Erstellung neuer Inhalte.
Wie unterscheidet sich BERT von anderen KI-Modellen?
BERT war zum Zeitpunkt seiner Veröffentlichung unter den vorhandenen KI-Modellen einzigartig, da es den Kontext verstehen konnte, in dem ein Wort verwendet wird.
Andere KI-Modelle konnten damals nur die Wörter vorhersagen, die auf eine Gruppe von Wörtern folgten. Das heißt, sie waren unidirektional. Das heißt, sie konnten Wörter nur in eine Richtung vorhersagen. In diesem Fall von links nach rechts.
BERT sagt jedoch das Wort voraus, das vor oder nach einer Wortgruppe steht. Dadurch ist es bidirektional, da es Wörter in beide Richtungen vorhersagen kann. Das heißt, es kann Wörter von links nach rechts und von rechts nach links vorhersagen.
So funktioniert BERT
BERT wurde darauf trainiert, den Kontext zu verstehen, in dem ein Wort verwendet wird. Zum Beispiel: lBetrachten wir zwei Sätze:
- Dies ist ein Stuhl
- Tom wird den Parteivorsitz übernehmen
„Chair“ hat in beiden Sätzen unterschiedliche Bedeutungen. Im ersten Satz bezieht es sich auf die Möbel, auf denen wir sitzen, während es im anderen Satz anzeigt, dass Tom die Party leiten wird.
Normalerweise konvertieren Machine-Learning-Modelle Wörter in Vektoren, also Zahlengruppen. Ein Machine-Learning-Modell wie word2vec kann beispielsweise in beiden Sätzen denselben Vektor für „Stuhl“ verwenden. Das heißt, es unterscheidet nicht zwischen „Stuhl“ als Möbelstück und „Stuhl“ als Verantwortlicher für ein Ereignis.
BERT verwendet jedoch unterschiedliche Vektoren für die Wörter, da es versteht, dass „chair“ in beiden Sätzen in unterschiedlichen Kontexten verwendet wird. Daher behandelt es sie, als wären sie unterschiedliche Wörter, obwohl sie genau gleich geschrieben sind.
Dies ist während des Trainings hilfreich, da BERT dadurch die Wörter, die in einem Satz vorkommen sollten, genauer vorhersagen kann.
Ein gängiges Training für maskierte Sprachmodelle wie BERT beinhaltet beispielsweise die Verwendung maskierter Wörter. Ein maskiertes Wort ist ein Wort, das während des Trainings absichtlich ausgeblendet oder durch einen Platzhalter ersetzt wird.
Beispiel: „Jedes Wochenende gehe ich gerne mit meinem Hund zur [MASKE], wo wir uns entspannen und die frische Luft genießen können.“
BERT müsste die Wörter vor und nach dem Platzhalter [MASK] analysieren und daraus das maskierte Wort vorhersagen. In diesem Fall könnte das maskierte Wort „Park“, „Strand“ oder „Landschaft“ sein, da dies Orte sind, an die man am Wochenende mit seinem Hund gehen könnte, um sich zu entspannen und frische Luft zu schnappen.
Diese Trainingsmethode unterscheidet sich von anderen KI-Modellen, die normalerweise nur die Wörter vor dem maskierten Wort bewerten und diese zur Vorhersage des maskierten Wortes verwenden.
Bei Suchanfragen identifiziert BERT die wichtigsten Wörter. Anschließend analysiert es die Wörter vor und nach der Suchanfrage und nutzt sie, um den Kontext zu verstehen, in dem sie im Hinblick auf das wichtige Wort verwendet werden. Dadurch kann BERT die Absicht einer Suchanfrage aufdecken.
Wie BERT die Google-Suchergebnisse verbessert
Google nutzt BERT, um die Absicht einer Suchanfrage zu verstehen. Dies ist besonders hilfreich, um die Absicht von Konversationsanfragen zu identifizieren. Long-Tail-Abfragenund Abfragen, die wichtige Präpositionen wie „für“ und „zu“ enthalten.
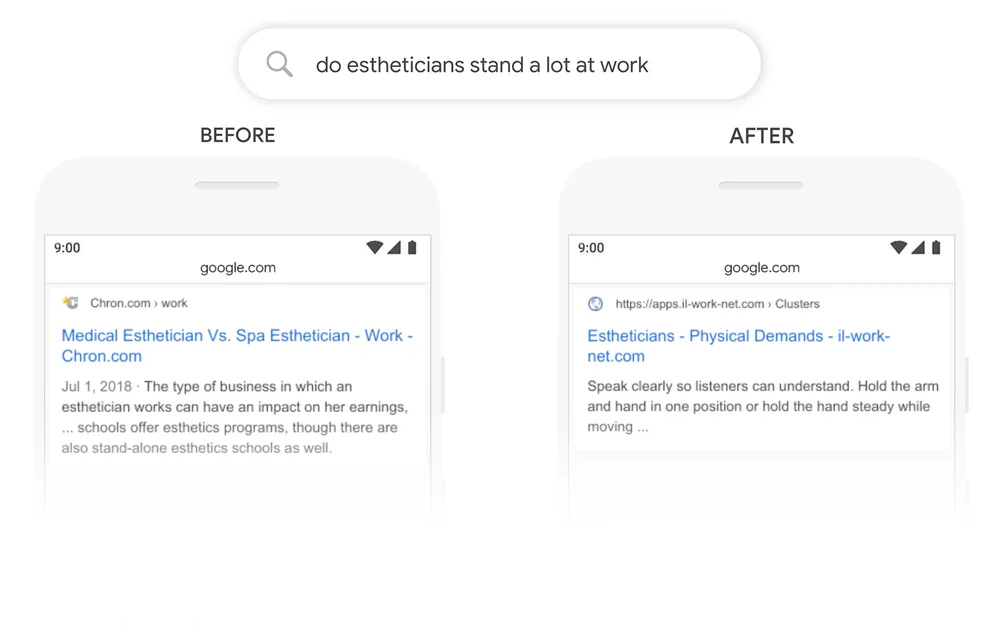
Das folgende Bild vergleicht beispielsweise die Ergebnisse, die Google für eine Suchanfrage mit BERT-Unterstützung anzeigt, mit einer, die nicht BERT-Unterstützung bietet.
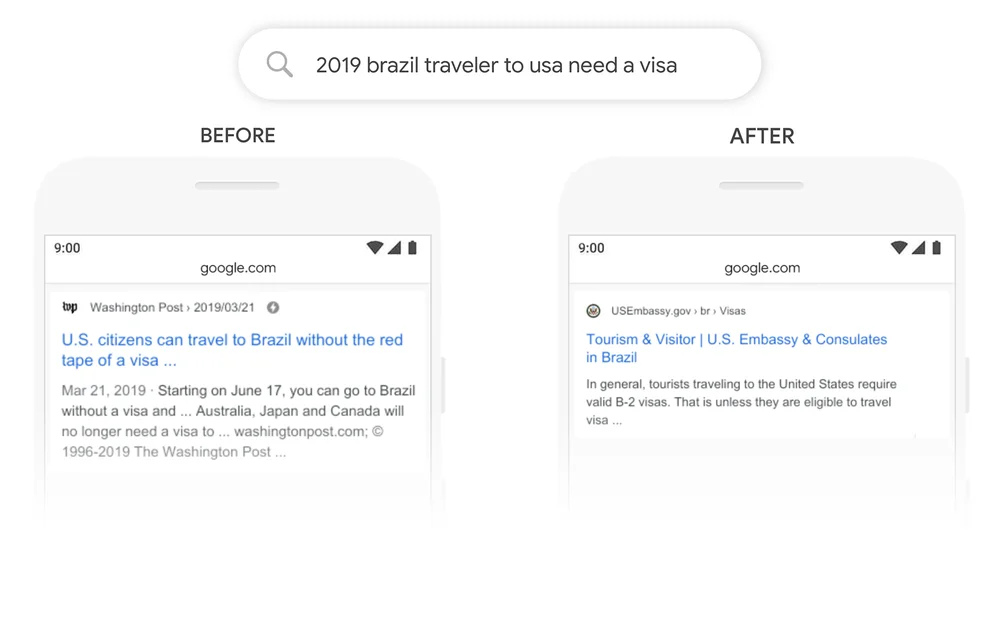
Im obigen Bild hat Google die Suchanfrage vor der Anwendung von BERT nicht verstanden und Ergebnisse zu US-Bürgern zurückgegeben, die nach Brasilien reisen. Nach der Anwendung von BERT wurden jedoch Ergebnisse zu brasilianischen Reisenden zurückgegeben, die in die USA reisen.
Im folgenden Suchergebnis hat Google „stand-alone“ in den Top-Ergebnissen mit der Suchanfrage „stand“ abgeglichen. Dies führte zu einem wenig hilfreichen Ergebnis, das die Anfrage nicht beantwortete. Mit BERT hat Google die Abfrage jedoch verstanden und ein relevanteres Ergebnis zurückgegeben.